
K8S监控-Prometheus
- Kubernetes
- 2024-11-28
- 7535热度
- 3评论
K8S监控-Prometheus
在 Kubernetes(K8s)中使用 Prometheus 进行监控时,有一些关键的指标和参数,通常需要关注以确保集群的健康和性能
1、API Server
| 参数 | 含义 |
|---|---|
| apiserver_request_duration_seconds | API 请求的响应时间 |
| apiserver_request_total | API 请求的总次数,区分成功与失败 |
| apiserver_dropped_requests_total | 丢失的请求数 |
| apiserver_long_running_queries | 长时间运行的查询 |
2、Controller Manager
| 参数 | 含义 |
|---|---|
| controller_manager_runs_total | 控制器管理器的执行次数 |
| controller_manager_duration_seconds | 控制器管理器运行的时间 |
3、Scheduler
| 参数 | 含义 |
|---|---|
| scheduler_e2e_duration_seconds | 调度的总时长 |
| scheduler_queue_latency_seconds | 队列延迟的时间 |
4、Node Metrics
| 参数 | 含义 |
|---|---|
| node_cpu_seconds_total | 节点的 CPU 使用时间 |
| node_memory_bytes | 节点的内存使用量 |
| node_disk_io_time_seconds_total | 节点磁盘 I/O 时间 |
| node_network_receive_bytes_total | 网络流量的接收字节数 |
| node_network_transmit_bytes_total | 网络流量的发送字节数 |
5、Kubelet
| 参数 | 含义 |
|---|---|
| kubelet_running_pods | 当前正在运行的 pod 数量 |
| kubelet_network_receive_bytes_total/kubelet_network_transmit_bytes_total | Kubelet 网络流量 |
| kubelet_cpu_usage_seconds_total | Kubelet 使用的 CPU 时间 |
| kubelet_memory_usage_bytes | Kubelet 使用的内存量 |
6、Kube Proxy
| 参数 | 含义 |
|---|---|
| kubeproxy_connections_open | 当前打开的连接数 |
| kubeproxy_errors_total | 代理组件的错误总数 |
7、Pod
| 参数 | 含义 |
|---|---|
| container_cpu_usage_seconds_total | 容器的 CPU 使用时间 |
| container_memory_usage_bytes | 容器的内存使用量 |
| container_memory_rss | 容器的常驻内存集大小 |
| container_network_receive_bytes_total/container_network_transmit_bytes_total | 容器的网络接收或发送字节数 |
| container_fs_usage_bytes | 容器使用的文件系统存储量 |
| container_fs_inodes_usage | 容器使用的文件系统 inode 数量 |
| kube_pod_container_status_restarts_total | Pod 容器重启的总次数 |
8、Controller
| 参数 | 含义 |
|---|---|
| kube_deployment_status_replicas | 当前 Deployment 的副本数量 |
| kube_replica_set_status_replicas | 当前 ReplicaSet 的副本数量 |
| kube_pod_status_ready | Pod 是否处于就绪状态 |
9、SVC/Node
| 参数 | 含义 |
|---|---|
| apiserver_request_total | 向 Kubernetes API Server 发起的请求总数 |
| kube_endpoint_address_available | 服务的端点是否可用 |
| service_request_duration_seconds | 服务请求的响应时间 |
| kube_node_status_allocatable_cpu_cores | 节点可分配的 CPU 核心数 |
| kube_node_status_allocatable_memory_bytes | 节点可分配的内存量 |
| kube_pod_container_resource_requests_cpu_cores | Pod 对 CPU 的请求 |
| kube_pod_container_resource_requests_memory_bytes | Pod 对内存的请求 |
Prometheus简介
Prometheus 是一个开源的监控和报警系统,专门设计用于大规模的分布式系统监控。它最初由 SoundCloud 开发,后来成为 CNCF(云原生计算基金会)的一部分。Prometheus 主要用于收集、存储、查询和可视化指标数据(metrics),并能够通过定义的规则触发报警。它在容器化环境和微服务架构中尤其流行,广泛应用于 Kubernetes、Docker 和云原生应用的监控。
Prometheus 的核心功能
1、数据采集:Prometheus 通过 HTTP 协议定期从被监控的应用或服务中拉取(Pull)指标数据。这些数据通常是以时间序列(Time Series)的形式存储,每个时间序列都有一个唯一的标识符,通常由 指标名称 和一组 标签(Labels)组成
2、时间序列存储:Prometheus 使用自己的时序数据库(TSDB)来存储监控数据,支持高效地存储和查询时间序列数据。这些数据按时间戳组织,可以精确到秒级,支持长期存储
3、强大的查询语言(PromQL):Prometheus 提供了一种称为 PromQL(Prometheus Query Language)的查询语言,允许用户以灵活的方式查询存储的时间序列数据。你可以使用 PromQL 来执行聚合、过滤、计算、切分等操作
4、自动发现服务: Prometheus 支持自动服务发现(Service Discovery),可以自动识别和抓取目标的指标数据。它支持多种服务发现机制,如 Kubernetes、Consul、DNS、EC2 等。对于 Kubernetes,Prometheus 可以自动发现各个 Pod 和服务,轻松集成在容器化环境中
5、报警功能: Prometheus 具有强大的报警功能,用户可以基于 PromQL 查询表达式设置报警规则。如果某个指标超过指定阈值,Prometheus 可以将警报发送给 Alertmanager(一个专门处理警报的组件),并通过电子邮件、Slack、PagerDuty 等渠道发送警报通知
6、Grafana 集成: Prometheus 生成的时间序列数据可以通过 Grafana 进行可视化,Grafana 提供了丰富的仪表板模板,用户可以非常方便地展示 Prometheus 采集的数据
Prometheus架构和工作流程

核心组件
1、Prometheus Server:Prometheus 生态最重要的组件,主要用于抓取和存储时间序列数据,同时提供数据的查询和告警策略的配置管理
2、Exporters:主要用来采集监控数据,比如主机的监控数据可以通过 node_exporter采集,MySQL 的监控数据可以通过 mysql_exporter 采集,之后 Exporter 暴露一个接口,比如/metrics,Prometheus 可以通过该接口采集到数据,常见的Exporter有:Node Exporter(监控主机(如 CPU、内存、磁盘、网络等)级别的指标)、Kube-State-Metrics(提供 Kubernetes 集群和资源(如 Pod、节点、部署等)的状态指标)、Blackbox Exporter(用于检查 HTTP、HTTPS、DNS 等服务的可用性)
3、Alertmanager: Alertmanager 用于接收来自 Prometheus 的报警,并根据报警规则执行相应的动作(如发送邮件、Slack 通知、Webhook 等)。它负责报警的抑制、分组和路由
4、Service Discovery: Prometheus 可以通过 服务发现机制 自动发现需要监控的目标,这对于动态变化的环境(如 Kubernetes、Docker 容器、云环境等)尤其重要
5、Push Gateway:Prometheus 本身是通过 Pull 的方式拉取数据,但是有些监控数据可能是短期的,如果没有采集数据可能会出现丢失。Push Gateway 可以用来解决此类问题,它可以用来接收数据,也就是客户端可以通过 Push 的方式将数据推送到 Push Gateway,之后 Prometheus 可以通过 Pull 拉取该数据
6、PromQL:PromQL 其实不算 Prometheus 的组件,它是用来查询数据的一种语法,比如查询数据库的数据,可以通过 SQL 语句,查询 Loki 的数据,可以通过 LogQL,查询 Prometheus 数据的叫做 PromQL
7、Grafana: Grafana 是一个开源的数据可视化工具,通常与 Prometheus 配合使用,用于展示Prometheus 收集的时间序列数据,提供丰富的图表和仪表盘
Prometheus工作流程
1、数据收集: Prometheus 使用 HTTP 轮询方式从目标(如 Kubernetes Pod、节点、应用程序)拉取监控指标。被监控的服务通常会暴露一个 /metrics 的 HTTP 接口,Prometheus 会定期访问这些接口以收集数据
2、存储: Prometheus 将收集到的指标数据存储在本地时序数据库中,并根据时间戳索引这些数据。每个指标数据都以时间序列的方式保存,这些时间序列数据由标签(如 pod、service、namespace)等维度进行区分
3、查询: Prometheus 提供 PromQL 查询语言,允许用户对存储的时间序列数据进行灵活查询。用户可以通过 PromQL 查询出如 CPU 使用率、内存占用等指标,并进行聚合分析、计算等操作
4、报警: 基于 PromQL 表达式,用户可以设置报警规则(如 CPU 使用率超过 80%)。当某个指标触发报警条件时,Prometheus 会将报警通知发送给 Alertmanager
5、可视化: 可视化方面,Prometheus 本身提供了一些基本的图表功能,但通常与 Grafana 配合使用,Grafana 提供了更强大、更友好的数据可视化功能,支持通过 Prometheus 数据源绘制各种图表、仪表板、报告等
Prometheus的安装
Prometheus的安装有多种方式,包括二进制安装、容器安装、Helm、Prometheus Operator和Kube-Prometheus Stack。本文档采用Kube-Prometheus Stack的方式进行安装
访问kube-prometheus的项目地址,查看K8S集群和当前技术栈的匹配信息,作者的K8S集群版本为1.30.x
https://github.com/prometheus-operator/kube-prometheus/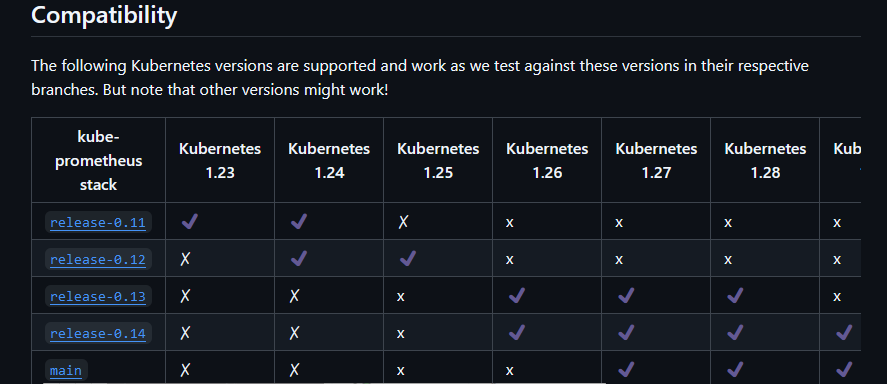
拉取对应版本的git包(注意:当前的网络问题和后面的镜像拉取问题,请参考作者的日志收集章节或云原生存储章节配置代理)
[root@master-01 ~]# git clone -b release-0.14 https://github.com/prometheus-operator/kube-prometheus.git
Cloning into 'kube-prometheus'...
remote: Enumerating objects: 20499, done.
remote: Counting objects: 100% (3921/3921), done.
remote: Compressing objects: 100% (285/285), done.
remote: Total 20499 (delta 3738), reused 3714 (delta 3617), pack-reused 16578 (from 1)
Receiving objects: 100% (20499/20499), 12.43 MiB | 1.20 MiB/s, done.
Resolving deltas: 100% (14112/14112), done.切换到manifests目录下,包含了创建Prometheus技术栈包含的所有资源,setup目录下包含了Prometheus的CRD定义。首先需要创建setup目录下的资源,这些 CRD 使 Kubernetes 可以处理不同的监控和告警资源
[root@master-01 manifests]# kubectl create -f setup/
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
namespace/monitoring created读者也可以用此方法进行创建(创建命名空间和 CRD,然后等待它们可用,然后再创建剩余资源 )
[root@master-01 manifests]# kubectl wait \
> --for condition=Established \
> --all CustomResourceDefinition \
> --namespace=monitoring
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/bgpfilters.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/caliconodestatuses.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/ipreservations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org condition met
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/redisclusters.cache.tongdun.net condition met
customresourcedefinition.apiextensions.k8s.io/redisstandbies.cache.tongdun.net condition met
customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com condition met
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com condition met等待资源声明完成,随后创建manifests目录中的其余资源(此处会创建非常多的资源,并且新版本的Prometheus-operator会在此处生成,旧版本在上一步会生成),读者可以在创建前配置持久化存储、修改SVC类型或者修改对应Pod资源的Replcation数量
[root@master-01 kube-prometheus]# kubectl apply -f manifests/
alertmanager.monitoring.coreos.com/main created
networkpolicy.networking.k8s.io/alertmanager-main created
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager-main created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
networkpolicy.networking.k8s.io/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-config created
secret/grafana-datasources created
configmap/grafana-dashboard-alertmanager-overview created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-grafana-overview created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-multicluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes-darwin created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
networkpolicy.networking.k8s.io/grafana created
prometheusrule.monitoring.coreos.com/grafana-rules created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
networkpolicy.networking.k8s.io/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
networkpolicy.networking.k8s.io/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
networkpolicy.networking.k8s.io/prometheus-k8s created
poddisruptionbudget.policy/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created
Warning: resource apiservices/v1beta1.metrics.k8s.io is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resouces created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io configured
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
Warning: resource clusterroles/system:aggregated-metrics-reader is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be usd on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader configured
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
networkpolicy.networking.k8s.io/prometheus-adapter created
poddisruptionbudget.policy/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
networkpolicy.networking.k8s.io/prometheus-operator created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
service/prometheus-operator created
serviceaccount/prometheus-operator created
servicemonitor.monitoring.coreos.com/prometheus-operator created查看容器状态,需要确保容器都处于正常运行状态
[root@master-01 manifests]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 14h
alertmanager-main-1 2/2 Running 0 14h
alertmanager-main-2 2/2 Running 0 14h
blackbox-exporter-74465f5fcb-z7q8z 3/3 Running 0 14h
grafana-b4bcd98cc-t6vnm 1/1 Running 0 14h
kube-state-metrics-59dcf5dbb-645v6 3/3 Running 0 14h
node-exporter-4vsd9 2/2 Running 0 14h
node-exporter-cfng2 2/2 Running 0 14h
node-exporter-m2lp5 2/2 Running 0 14h
node-exporter-pd4v9 2/2 Running 0 14h
node-exporter-x9sqm 2/2 Running 0 14h
prometheus-adapter-5794d7d9f5-bdrh9 1/1 Running 0 14h
prometheus-adapter-5794d7d9f5-tkwz2 1/1 Running 0 14h
prometheus-k8s-0 2/2 Running 0 14h
prometheus-k8s-1 2/2 Running 0 14h
prometheus-operator-6f948f56f8-tft4h 2/2 Running 0 14h修改Gafana的SVC类型为NodePort
[root@master-01 manifests]# kubectl edit -n monitoring service grafana
service/grafana edited
[root@master-01 manifests]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.96.85.152 <none> 9093/TCP,8080/TCP 14h
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 14h
blackbox-exporter ClusterIP 10.96.200.93 <none> 9115/TCP,19115/TCP 14h
grafana NodePort 10.96.214.185 <none> 3000:30584/TCP 14h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 14h
node-exporter ClusterIP None <none> 9100/TCP 14h
prometheus-adapter ClusterIP 10.96.28.210 <none> 443/TCP 14h
prometheus-k8s ClusterIP 10.96.204.197 <none> 9090/TCP,8080/TCP 14h
prometheus-operated ClusterIP None <none> 9090/TCP 14h
prometheus-operator ClusterIP None <none> 8443/TCP 14hGrafana 默认登录的账号密码为 admin/admin。然后相同的方式更改 Prometheus 的 Service 为NodePort
[root@master-01 manifests]# kubectl edit -n monitoring service prometheus-k8s
service/prometheus-k8s edited
[root@master-01 manifests]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.96.85.152 <none> 9093/TCP,8080/TCP 14h
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 14h
blackbox-exporter ClusterIP 10.96.200.93 <none> 9115/TCP,19115/TCP 14h
grafana NodePort 10.96.214.185 <none> 3000:30584/TCP 14h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 14h
node-exporter ClusterIP None <none> 9100/TCP 14h
prometheus-adapter ClusterIP 10.96.28.210 <none> 443/TCP 14h
prometheus-k8s NodePort 10.96.204.197 <none> 9090:32675/TCP,8080:32446/TCP 14h
prometheus-operated ClusterIP None <none> 9090/TCP 14h
prometheus-operator ClusterIP None <none> 8443/TCP 14h通过浏览器访问,访问格式IP+NP端口(注意:由于官方为了安全性考虑,为Pod配置了NetworkPolicy,所以直接访问是不行的,需要将之前的网络策略删除)
[root@master-01 manifests]# kubectl delete networkpolicy --all -n monitoring
networkpolicy.networking.k8s.io "alertmanager-main" deleted
networkpolicy.networking.k8s.io "blackbox-exporter" deleted
networkpolicy.networking.k8s.io "grafana" deleted
networkpolicy.networking.k8s.io "kube-state-metrics" deleted
networkpolicy.networking.k8s.io "node-exporter" deleted
networkpolicy.networking.k8s.io "prometheus-adapter" deleted
networkpolicy.networking.k8s.io "prometheus-k8s" deleted
networkpolicy.networking.k8s.io "prometheus-operator" deleted[root@master-01 manifests]# telnet 192.168.132.236 30277
Trying 192.168.132.236...
Connected to 192.168.132.236.
Escape character is '^]'.Grafana访问界面,登录后提示需要修改密码。登录到主界面后,依次单击Home→Explore→Metrics按钮,即可观察集群的资源图表

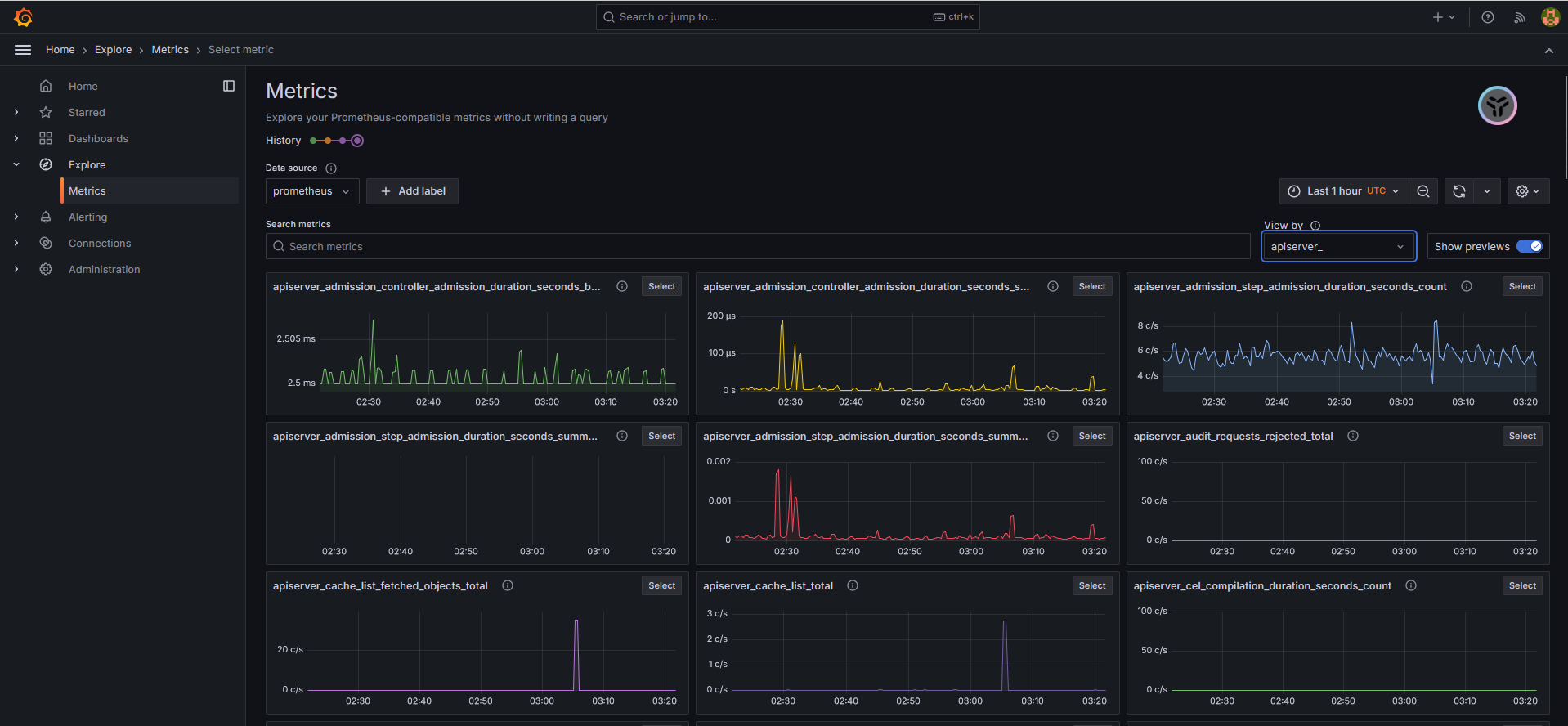
Prometheus的UI也是同样的访问方法(http://192.168.132.236:32675/)。注意:刚开始的时候会出现告警,此时可以忽略
Prometheus监控数据来源
非云原生的监控一般采用exporter进行监控,而云原生的应用的一般通过服务自身暴露的/metrics接口让Prometheus进行pull采集监控信息
比如,node-exporter监听的9100端口,其实就是监控采集的数据来源
[root@master-01 manifests]# ps -aux | grep node_exporter
nfsnobo+ 16629 0.8 0.3 1242204 18672 ? Ssl Nov24 13:14 /bin/node_exporter --web.listen-address=127.0.0.1:9100 --path.sysfs=/host/sys --path.rootfs=/host/root --path.udev.data=/host/root/run/udev/data --no-collector.wifi --no-collector.hwmon --no-collector.btrfs --collector.filesystem.mount-points-exclude=^/(dev|proc|sys|run/k3s/containerd/.+|var/lib/docker/.+|var/lib/kubelet/pods/.+)($|/) --collector.netclass.ignored-devices=^(veth.*|[a-f0-9]{15})$ --collector.netdev.device-exclude=^(veth.*|[a-f0-9]{15})$
root 95083 0.0 0.0 112828 2304 pts/0 S+ 23:24 0:00 grep --color=auto node_exporter
[root@master-01 manifests]# ss -lntp | grep 9100
LISTEN 0 16384 192.168.132.169:9100 *:* users:(("kube-rbac-proxy",pid=17188,fd=3))
LISTEN 0 16384 127.0.0.1:9100 *:* users:(("node_exporter",pid=16629,fd=3))
[root@master-01 manifests]# curl 127.0.0.1:9100/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.0034e-05
go_gc_duration_seconds{quantile="0.25"} 4.7561e-05
go_gc_duration_seconds{quantile="0.5"} 5.7244e-05
go_gc_duration_seconds{quantile="0.75"} 6.7569e-05
go_gc_duration_seconds{quantile="1"} 0.078837684
go_gc_duration_seconds_sum 4.79348581
go_gc_duration_seconds_count 28174
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 8Grafana导入数据来源和下载模版,即可对这些数据进行可视化的展示
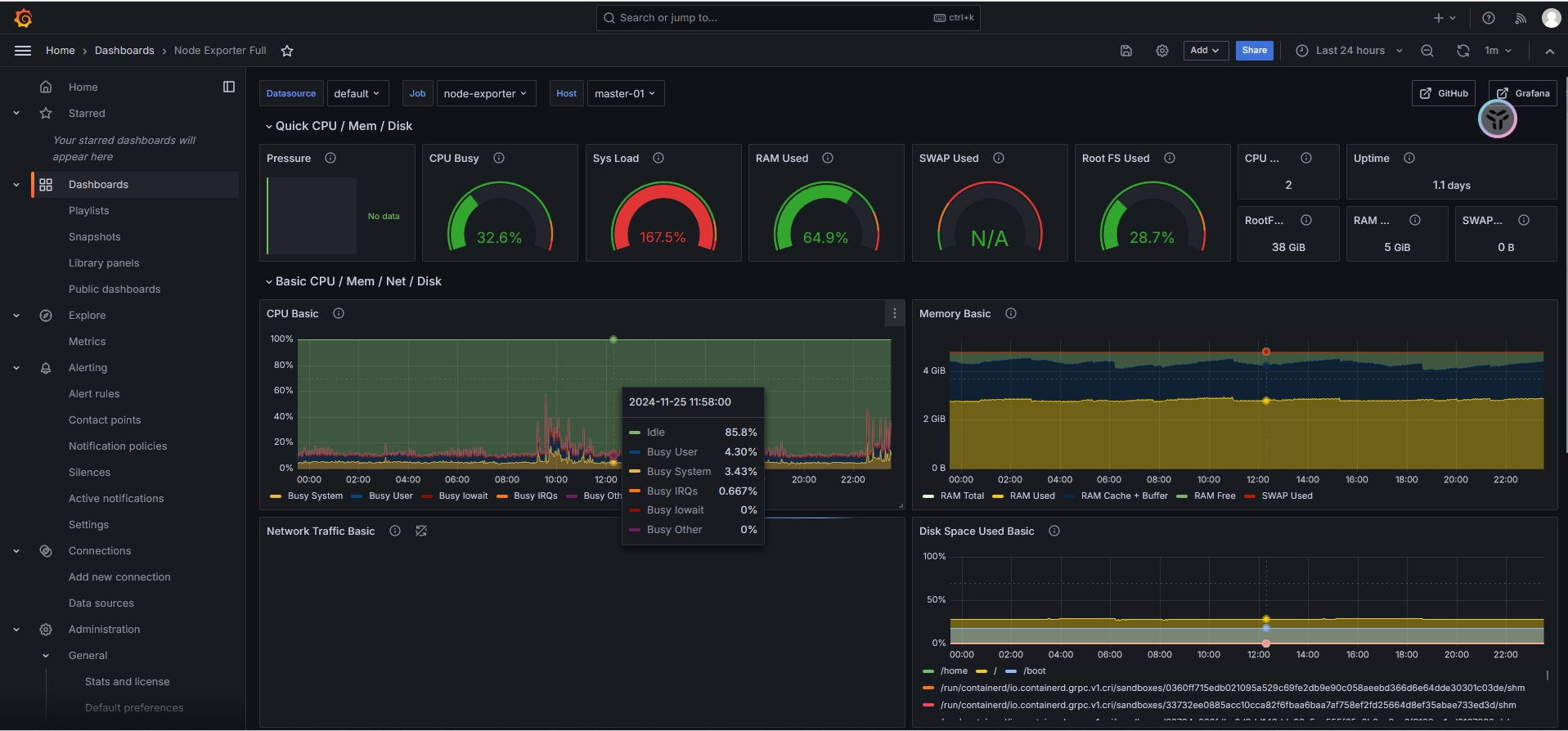
常用的exporter工具如下
| 类型 | Exporter |
|---|---|
| 数据库 | MySQL Exporter, Redis Exporter, MongoDB Exporter, MSSQL Exporter |
| 硬件 | Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter, Node Exporter |
| 消息队列 | Beanstalkd Exporter, Kafka Exporter, NSQ Exporter, RabbitMQ Exporter |
| 存储 | Ceph Exporter, Gluster Exporter, HDFS Exporter, ScaleIO Exporter |
| HTTP 服务 | Apache Exporter, HAProxy Exporter, Nginx Exporter |
| API 服务 | AWS ECS Exporter, Docker Cloud Exporter, Docker Hub Exporter, GitHub Exporter |
| 日志 | Fluentd Exporter, Grok Exporter |
| 监控系统 | Collectd Exporter, Graphite Exporter, InfluxDB Exporter, Nagios Exporter, SNMP Exporter |
| 其它 | Blackbox Exporter, JIRA Exporter, Jenkins Exporter, Confluence Exporter |
云原生ETCD监控
ServiceMonitor 是 Prometheus Operator 提供的一个 Custom Resource (CR),它用于定义 Prometheus 如何抓取 Kubernetes 服务(Service)暴露的监控数据。ServiceMonitor 的主要作用是通过 Kubernetes 服务(Service)发现并抓取暴露的指标
ServiceMonitor 通过定义 spec.selector 和 spec.endpoints 来指定要抓取的目标服务(Service)和暴露的端口。ServiceMonitor 还支持其他配置,如 interval(抓取频率)、path(指标端点路径)、scheme(抓取协议)等。ServiceMonitor 配置完成后,Prometheus Operator 会定期查询 Kubernetes API,根据 ServiceMonitor 定义的规则来自动发现和抓取对应服务的指标。
测试访问Etcd Metrics接口
[root@master-01 etcd]# curl -s --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://192.168.132.169:2379/metrics -k | tail -10
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes 1.8446744073709552e+19
# HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served.
# TYPE promhttp_metric_handler_requests_in_flight gauge
promhttp_metric_handler_requests_in_flight 1
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 2
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0创建Etcd的Service以及Endpoint
[root@master-01 ~]# vim etcd-svc.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.132.169
- ip: 192.168.132.170
- ip: 192.168.132.171
ports:
- name: https-metrics
port: 2379 # etcd 端口
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: etcd-prom
name: etcd-prom
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 2379
protocol: TCP
targetPort: 2379
type: ClusterIP创建资源并查看对应的ClusterIP(注意:该SVC是创建在kube-system命名空间下的,其次如果读者有配置代理的话,请将对应的ClusterIP放行,否则monitor无法采集数据)
[root@master-01 ~]# kubectl create -f etcd-svc.yaml
endpoints/etcd-prom created
service/etcd-prom created[root@master-01 manifests]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.96.116.30 <none> 2379/TCP 5m48s[root@master-01 manifests]# kubectl get endpoints -n kube-system
NAME ENDPOINTS AGE
etcd-prom 192.168.132.169:2379,192.168.132.170:2379,192.168.132.171:2379 6m2s对SVC的ClusterIP进行访问测试(注意:只有该步骤成功才能继续往下操作,否则是获取不到数据的)
[root@master-01 ~]# curl -s --cert /etc/kubernetes/pki/etcd/server.crt --key /etc/kubernetes/pki/etcd/server.key https://10.96.116.30:2379/metrics -k | tail -2
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0创建Etcd的Secret(注意:证书路径需要根据实际路径填写)
[root@master-01 ~]# kubectl create secret generic etcd-ssl --from-file=/etc/kubernetes/pki/etcd/ca.crt --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/server.key -n monitoring
secret/etcd-ssl created将Secret挂载到Prometheus容器上
[root@master-01 ~]# kubectl edit prometheus -n monitoring k8s
spec:
...省略部分输出...
secrets:
- etcd-ssl
...省略部分输出...
prometheus.monitoring.coreos.com/k8s edited挂载完成后,可以观察到prometheus容器开始重启
[root@master-01 ~]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 38h
alertmanager-main-1 2/2 Running 0 38h
alertmanager-main-2 2/2 Running 0 38h
blackbox-exporter-74465f5fcb-z7q8z 3/3 Running 0 38h
grafana-b4bcd98cc-t6vnm 1/1 Running 0 38h
kube-state-metrics-59dcf5dbb-645v6 3/3 Running 0 38h
node-exporter-4vsd9 2/2 Running 0 38h
node-exporter-cfng2 2/2 Running 0 38h
node-exporter-m2lp5 2/2 Running 0 38h
node-exporter-pd4v9 2/2 Running 0 38h
node-exporter-x9sqm 2/2 Running 0 38h
prometheus-adapter-5794d7d9f5-bdrh9 1/1 Running 0 38h
prometheus-adapter-5794d7d9f5-tkwz2 1/1 Running 0 38h
prometheus-k8s-0 2/2 Running 0 38h
prometheus-k8s-1 0/2 Init:0/1 0 103s
prometheus-operator-6f948f56f8-tft4h 2/2 Running 0 38h查看证书是否挂载到容器内部
[root@master-01 ~]# kubectl exec -n monitoring prometheus-k8s-0 -c prometheus -- ls /etc/prometheus/secrets/etcd-ssl/
ca.crt
server.crt
server.key创建 Etcd 的 ServiceMonitor
[root@master-01 ~]# cat servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd
namespace: monitoring
labels:
app: etcd
spec:
jobLabel: k8s-app
endpoints:
- interval: 30s # 采集频率
port: https-metrics # 这个 port 对应 Service.spec.ports.name
scheme: https # 采集协议
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-ssl/ca.crt # CA 证书路径
certFile: /etc/prometheus/secrets/etcd-ssl/server.crt # 客户端证书路径
keyFile: /etc/prometheus/secrets/etcd-ssl/server.key # 客户端证书私钥路径
insecureSkipVerify: true # 关闭证书校验
selector:
matchLabels:
app: etcd-prom # 与 Service 的标签匹配
namespaceSelector:
matchNames:
- kube-system # 在 kube-system 命名空间中寻找 Service创建资源并查看资源状态
[root@master-01 ~]# kubectl create -f servicemonitor.yaml
servicemonitor.monitoring.coreos.com/etcd created
[root@master-01 ~]# kubectl get servicemonitors.monitoring.coreos.com -n monitoring etcd
NAME AGE
etcd 5m1s登录Grafana的UI界面,依次单击Dashboards→New→New dashboard→Import dashboard,在出现的Import dashboard界面填写心仪的dashboard界面即可。下面附带官网提供的dashboard模板链接
https://grafana.com/grafana/dashboards/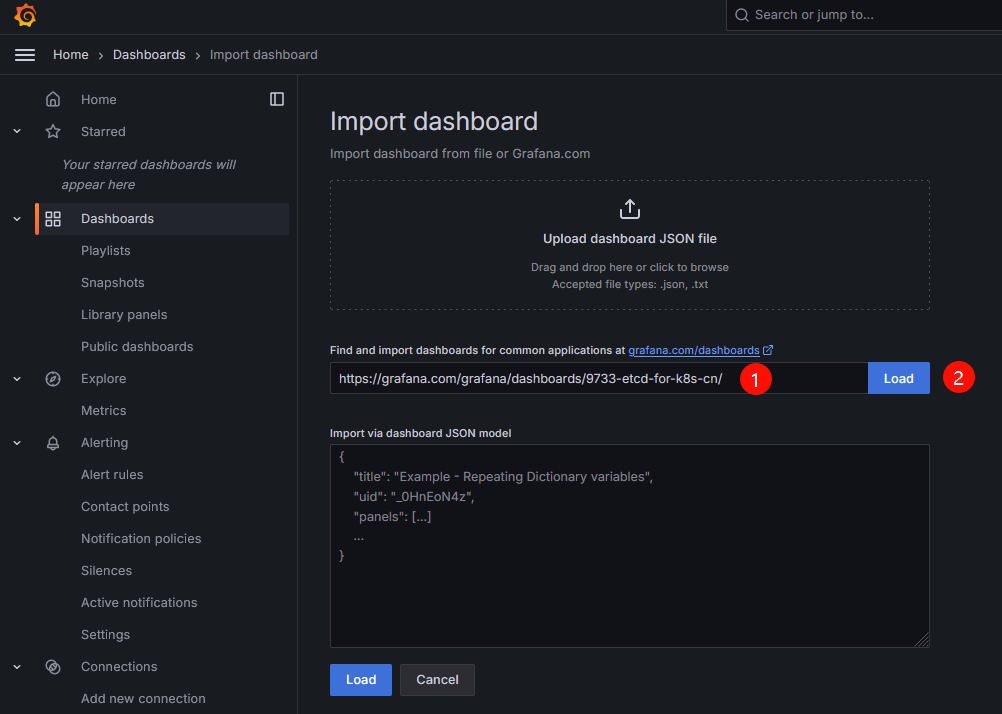
添加dashboard的名称和添加prometheus数据源后,单击import按钮,等待一段时间即可查看Etcd监控数据
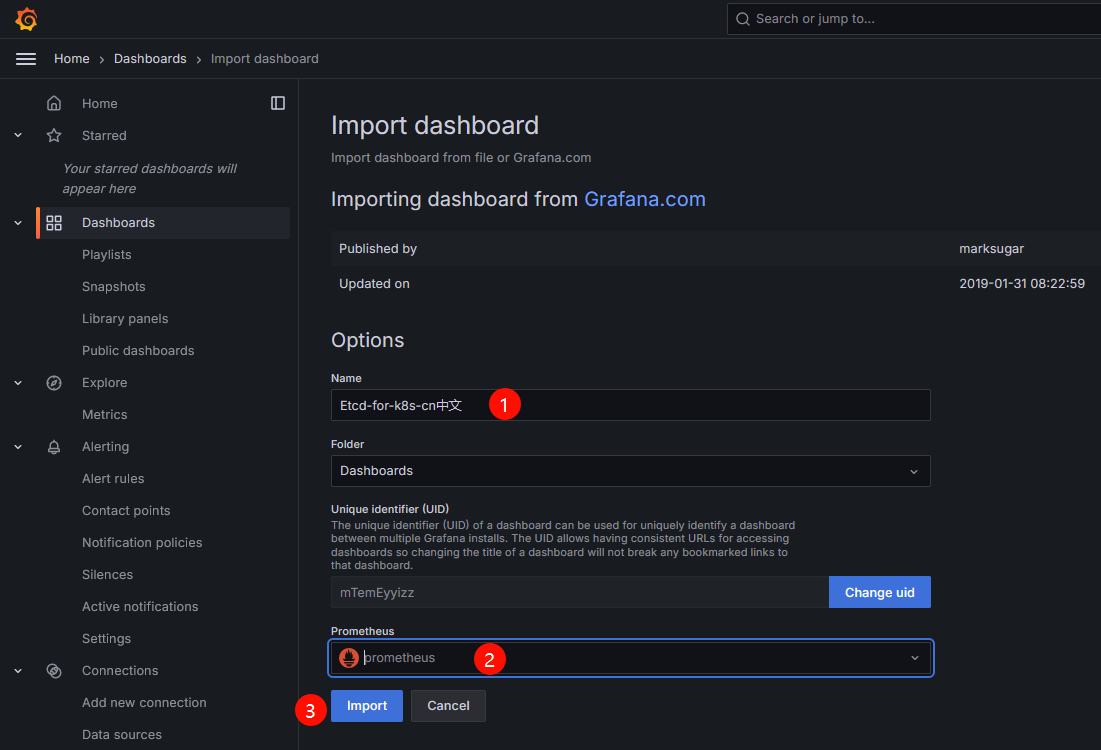

非云原生监控 Exporter
使用 MySQL 作为测试用例,演示如何使用 Exporter 监控非云原生应用
部署Mysql服务,为Mysql设置密码,并暴露3306端口
[root@master-01 ~]# kubectl create deploy mysql --image=registry.cn-beijing.aliyuncs.com/dotbalo/mysql:5.7.23
deployment.apps/mysql created[root@master-01 ~]# kubectl set env deploy/mysql MYSQL_ROOT_PASSWORD=mysql
deployment.apps/mysql env updated[root@master-01 ~]# kubectl expose deploy mysql --port 3306
service/mysql exposed检查容器和Service服务是否正常
[root@master-01 ~]# kubectl get po -l app=mysql
NAME READY STATUS RESTARTS AGE
mysql-7d6ff9c689-m5smn 1/1 Running 0 32s[root@master-01 ~]# kubectl get svc -l app=mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP 10.96.175.244 <none> 3306/TCP 22s登录Mysql,创建 Exporter 所需的用户和权限
[root@master-01 ~]# kubectl exec -it mysql-7d6ff9c689-m5smn -- bash
root@mysql-7d6ff9c689-m5smn:/# mysql -uroot -pmysql
mysql: [Warning] Using a password on the command line interface can be insecure .
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.23 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> create user 'exporter'@'%' identified by 'exporter' with MAX_USER_CONNECTIONS 3;
Query OK, 0 rows affected (0.02 sec)
mysql> grant process,replication client,select on *.* to 'exporter'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> quit
Bye
root@mysql-7d6ff9c689-m5smn:/# exit
exit配置 MySQL Exporter 采集 MySQL 监控数据(注意 DATA_SOURCE_NAME 的配置,需要将 exporter:exporter@(mysql.default:3306)改成 自 己 的 实 际 配 置 , 格 式 如 下
USERNAME:PASSWORD@MYSQL_HOST_ADDRESS:MYSQL_PORT)
[root@master-01 ~]# vim mysql-exporter
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
k8s-app: mysql-exporter
template:
metadata:
labels:
k8s-app: mysql-exporter
spec:
containers:
- name: mysql-exporter
image: registry.cn-beijing.aliyuncs.com/dotbalo/mysqld-exporter
env:
- name: DATA_SOURCE_NAME
value: "exporter:exporter@(mysql.default:3306)/"
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9104
---
apiVersion: v1
kind: Service
metadata:
name: mysql-exporter
namespace: monitoring
labels:
k8s-app: mysql-exporter
spec:
type: ClusterIP
selector:
k8s-app: mysql-exporter
ports:
- name: api
port: 9104
protocol: TCP[root@master-01 ~]# kubectl create -f mysql-exporter
deployment.apps/mysql-exporter created
service/mysql-exporter created[root@master-01 ~]# kubectl get -f mysql-exporter
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/mysql-exporter 1/1 1 1 21h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/mysql-exporter ClusterIP 10.96.191.150 <none> 9104/TCP 21h对暴露的SVC端口进行访问测试(读者也可以直接使用curl serviceIP+Port进行访问)
[root@master-01 ~]# kubectl port-forward -n monitoring svc/mysql-exporter 9104: 9104
Forwarding from 127.0.0.1:9104 -> 9104
Forwarding from [::1]:9104 -> 9104
Handling connection for 9104打开新的终端窗口,访问127.0.0.1:9104/metrics(上面的命令就是将本地9104端口与容器的9104端口进行映射)
[root@master-01 ~]# curl http://127.0.0.1:9104/metrics | tail -4
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collec tion cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0
go_gc_duration_seconds{quantile="0.25"} 0配置mysql ServiceMonitor,并创建资源
[root@master-01 ~]# vim mysqlmonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: mysql-exporter
namespace: monitoring
labels:
k8s-app: mysql-exporter
spec:
jobLabel: k8s-app
endpoints:
- port: api
interval: 30s
scheme: http
selector:
matchLabels:
k8s-app: mysql-exporter
namespaceSelector:
matchNames:
- monitoring等待数据采集完成,通过Prometheus UI界面可以看到mysql-exporter已经上线(依次单击Status→Service Discovery)
serviceMonitor/monitoring/mysql-exporter/0 (1 / 47 active targets)导入Grafana Dashboard界面,即可将监控数据可视化,下面附带Dashboard链接
https://grafana.com/grafana/dashboards/14057-mysql/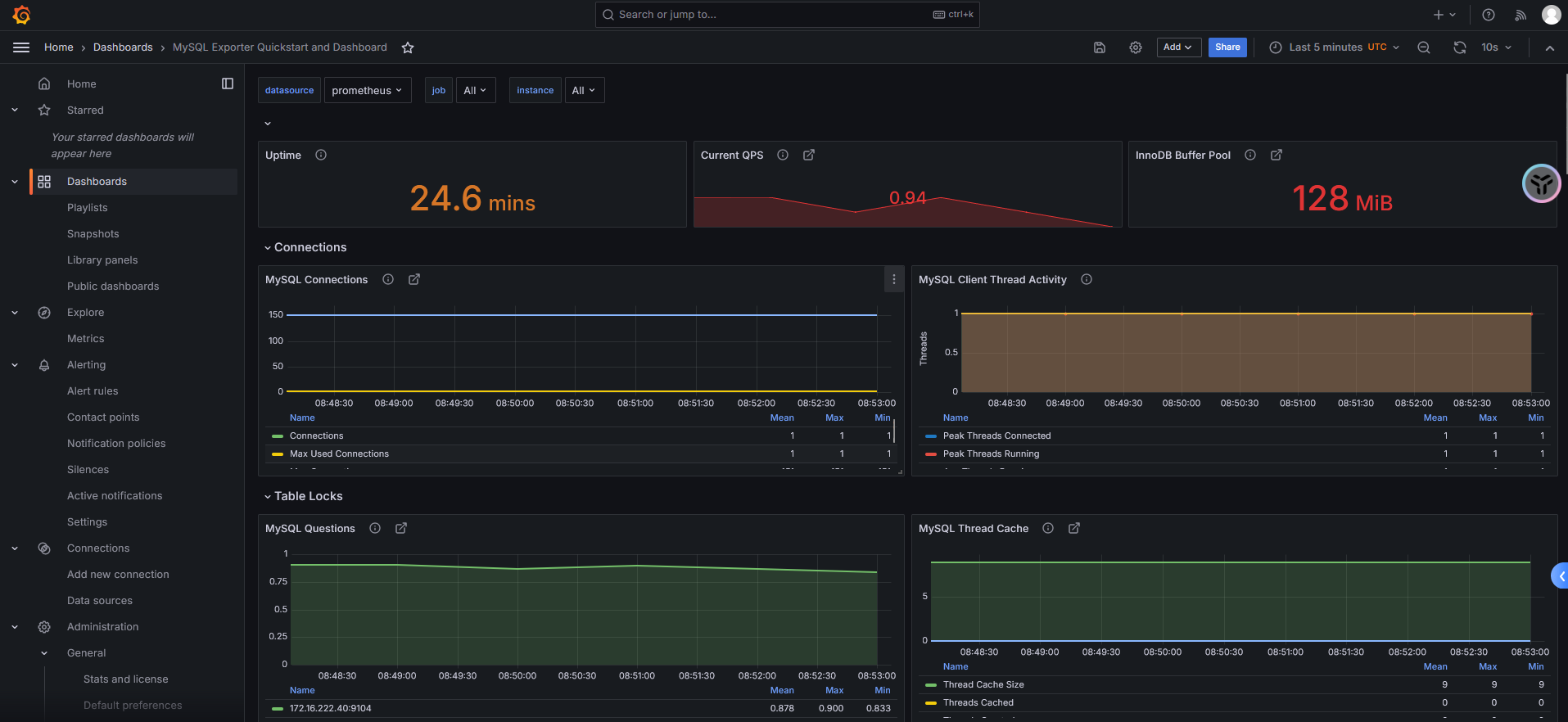
Prometheus无法监控kube-controller-manager和kube-scheduler
表现:Prometheus界面无法观察到数据,并且两个组件都处于Firing状态
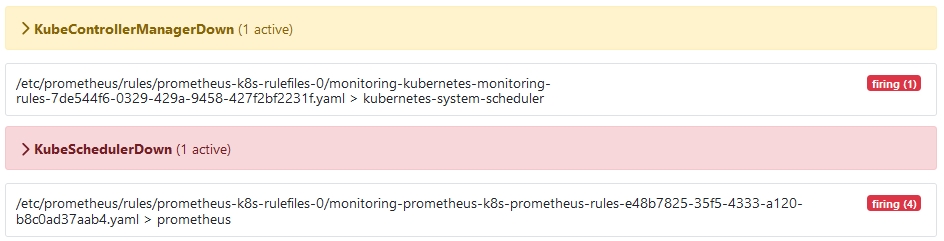
原因:两个组件都只监听127.0.0.1,Prometheus的ServiceMonitor没有找到组件对应的Service
解决方法如下:
所有master节点修改kube-controller-manager配置文件,将监听地址修改为0.0.0.0(注意:Kubeadm安装和二进制安装的路径可能不一致,请读者按照实际情况进行修改)
[root@master-01 ~]# vim /etc/kubernetes/manifests/kube-controller-manager.yaml
...省略部分输出...
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=172.16.0.0/16
- --cluster-name=kubernetes
...省略部分输出...在/etc/kubernetes/manifests/目录下的文件为集群的静态容器配置,配置完成后不需要手动重启容器,集群会自动读取配置文件进行重启容器
[root@master-01 kubernetes]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
...省略部分输出...
kube-apiserver-master-03 1/1 Running 21 (2d3h ago) 28d
kube-controller-manager-master-01 1/1 Running 0 5h23m
kube-controller-manager-master-02 1/1 Running 0 42s
kube-controller-manager-master-03 0/1 Pending 0 1s
kube-proxy-84trv 1/1 Running 6 (2d3h ago) 28d
...省略部分输出...修改完成后,查看ServiceMonitor配置,可以观察到kube-controller-manager组件对应匹配的命名空间为kube-system,对应匹配的标签为app.kubernetes.io/name: kube-controller-manager,对应的service端口为https-metrics
[root@master-01 ~]# kubectl get servicemonitors.monitoring.coreos.com -n monitoring | egrep 'kube-controller-manager|kube-scheduler'
kube-controller-manager 2d19h
kube-scheduler 2d19h[root@master-01 ~]# kubectl get servicemonitors.monitoring.coreos.com -n monitoring kube-controller-manager -oyaml | tail -20
insecureSkipVerify: true
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 5s
metricRelabelings:
- action: drop
regex: process_start_time_seconds
sourceLabels:
- __name__
path: /metrics/slis
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-controller-manager检查kube-system命名空间下并没有对应的Service
[root@master-01 ~]# kubectl get service -n kube-system -l app.kubernetes.io/name=kube-controller-manager
No resources found in kube-system namespace.创建kube-controller-manager对应的service,新版本对应监听的端口为10257(注意:labels和ports名称要与servicemonitor相匹配)
[root@master-01 ~]# vim controller-svc.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager-prom
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.132.169
- ip: 192.168.132.170
- ip: 192.168.132.171
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager-prom
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
sessionAffinity: None
type: ClusterIP[root@master-01 ~]# kubectl create -f controller-svc.yaml
endpoints/kube-controller-manager-prom created
service/kube-controller-manager-prom created
[root@master-01 ~]# kubectl get service -n kube-system -l app.kubernetes.io/name=kube-controller-manager
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-controller-manager-prom ClusterIP 10.96.22.199 <none> 10257/TCP 5s注意!!旧版本的kube-controller-manager为HTTP协议,可以直接进行测试,但是新版本换成了HTTPS协议,直接访问测试会提示没有权限或者返回空。解决方案参见以下链接:重新编写一个clusterrole,权限是对metrics接口有get权限,创建clusterrolebinding,绑定到某个serviceaccount上,然后通过对应的Token构造HTTPS头部进行访问
https://zhuanlan.zhihu.com/p/601741895完成上述操作后,Prometheus上关于controller-manager的告警会消失,并且在Service Discovery界面会出现关于controller-manager的监控项
serviceMonitor/monitoring/kube-controller-manager/0 (3 / 28 active targets)
serviceMonitor/monitoring/kube-controller-manager/1 (3 / 28 active targets)恢复kube-scheduler组件告警的方法跟controller-manager相似,master节点修改/etc/kubernetes/manifests/kube-scheduler.yaml文件的监听端口为0.0.0.0
[root@master-01 ~]# vim /etc/kubernetes/manifests/kube-scheduler.yaml
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
...省略部分输出...静态容器自动重启
[root@master-01 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-proxy-rjf4q 1/1 Running 6 (2d19h ago) 29d
kube-scheduler-master-01 1/1 Running 0 18s
kube-scheduler-master-02 1/1 Running 0 21s
kube-scheduler-master-03 1/1 Running 0 22s查看kube-scheduler的servicemonitor,检查是否有对应的Service,若无则创建(kube-scheduler监听的端口为10259)
[root@master-01 ~]# ss -lntp | grep kube-scheduler
LISTEN 0 16384 [::]:10259 [::]:* users:(("kube-scheduler",pid=67358,fd=3))[root@master-01 ~]# kubectl get servicemonitors.monitoring.coreos.com -n monitoring kube-scheduler -oyaml | tail -12
path: /metrics/slis
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-scheduler[root@master-01 ~]# vim scheduler-svc.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler-prom
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.132.169
- ip: 192.168.132.170
- ip: 192.168.132.171
ports:
- name: https-metrics
port: 10259
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler-prom
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10259
protocol: TCP
targetPort: 10259
sessionAffinity: None
type: ClusterIP创建完成后,Prometheus上的告警消失
[root@master-01 ~]# kubectl create -f scheduler.yaml
endpoints/kube-scheduler-prom created
service/kube-scheduler-prom created
[root@master-01 ~]# kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-scheduler
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-scheduler-prom ClusterIP 10.96.87.125 <none> 10259/TCP 26sserviceMonitor/monitoring/kube-scheduler/0 (3 / 31 active targets)
serviceMonitor/monitoring/kube-scheduler/1 (3 / 31 active targets)通过 Service Monitor 监控应用时,如果监控没有找到目标主机的排查步骤时,排查步骤大致如下:
1、 确认 Service Monitor 是否成功创建
2、确认 Prometheus 是否生成了相关配置
3、确认存在 Service Monitor 匹配的 Service
4、确认通过 Service 能够访问程序的 Metrics 接口
5、确认 Service 的端口和 Scheme 和 Service Monitor 一致
黑盒监控
Prometheus 黑盒监控(Blackbox Exporter)是 Prometheus 生态中一个非常重要的组件,通常用于监控无法直接暴露指标的外部服务,比如 HTTP、HTTPS、DNS、TCP 等协议的服务。黑盒监控并不依赖于被监控目标本身的指标导出,而是通过主动发起请求、检查服务的可用性来评估目标服务的健康状态
新版 Prometheus Stack 已经默认安装了 BlackboxExporter
[root@master-01 ~]# kubectl get servicemonitors -n monitoring -l app.kubernetes.io/name=blackbox-exporter
NAME AGE
blackbox-exporter 4d2hBlackboxExporter同时也会创建一个 Service,可以通过该 Service 访问 Blackbox Exporter 并传递一些参数
[root@master-01 ~]# kubectl get svc -n monitoring -l app.kubernetes.io/name=blackbox-exporter
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blackbox-exporter ClusterIP 10.96.200.93 <none> 9115/TCP,19115/TCP 4d2h检测blog.caijxlinux.work网站的状态(注意:使用任何一个公网域名或者公司内的域名探测都可以,若读者有使用代理,请unset http_proxy变量和https_proxy变量,否则Service无法访问对应的域名)
[root@master-01 ~]# curl -s "http://10.96.200.93:19115/probe?target=blog.caijxlinux.work&module=http_2xx" | tail -1
probe_tls_version_info{version="TLS 1.2"} 1| 参数 | 解析 |
|---|---|
| probe | 接口地址 |
| target | 检测目标 |
| module | 使用对应的模块检测 |
Prometheus静态配置
考虑到有些读者可能使用传统的安装方法进行安装,如二进制等,需要使用静态文件更新Prometheus配置,所以使用黑盒监控作为例子,演示在集群内部如何使用静态配置添加监控
创建prometheus-additional.yaml文件,将此文件配置为Secret,作为Prometheus的静态配置
[root@master-01 ~]# touch prometheus-additional.yaml
[root@master-01 ~]# kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
secret/additional-configs created编辑Prometheus的配置文件,添加以下内容
[root@master-01 ~]# kubectl edit prometheus -n monitoring k8s
...省略部分输出...
spec:
additionalScrapeConfigs:
key: prometheus-additional.yaml
name: additional-configs
optional: true
...省略部分输出...添加完成后,写入对应的监控内容到prometheus-additional.yaml文件内
[root@master-01 ~]# vim prometheus-additional.yaml
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
static_configs:
- targets:
- https://blog.caijxlinux.work # Target to probe with http.
- https://www.baidu.com # Target to probe with https.
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: blackbox-exporter:19115 # The blackbox exporter's real hostname:port.热更新Secret
[root@master-01 ~]# kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml --dry-run=client -oyaml | kubectl replace -f - -n monitoring
secret/additional-configs replaced等待一段时间后,打开Prometheus UI界面,依次单击Status→Targets,即可观察到对应的黑盒监控

监控处于正常状态后,在Grafana UI界面,导入黑盒监控模板,即可将监控结果可视化。在下方附带图表链接

https://grafana.com/grafana/dashboards/13659Prometheus监控Windows主机
下载对应的Exporter到Windows主机内(类似于zabbix-agent),选择安装的版本为windows_exporter-0.30.0-rc.0-amd64.msi
https://github.com/prometheus-community/windows_exporter/releases/tag/v0.30.0-rc.0在Windows主机安装完成后,可以通过CMD查看暴露的端口为9182
netstat -anio
TCP 0.0.0.0:9182 0.0.0.0:0 LISTENING 26632在prometheus-additional.yaml文件内添加配置
- job_name: 'WindowsServerMonitor'
static_configs:
- targets:
- "192.168.132.1:9182"
labels:
server_type: 'windows'
relabel_configs:
- source_labels: [__address__]
target_label: instance热更新Secret
[root@master-01 ~]# kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml --dry-run=client -oyaml | kubectl replace -f - -n monitoring
secret/additional-configs replaced在Prometheus UI查看到对应的监控数据,导入Grafana模板即可。此处不再赘述


https://grafana.com/grafana/dashboards/12566Prometheus 语法 PromQL
PromQL是查询 Prometheus 数据的强大工具,可以执行实时分析、计算和监控规则。读者需要掌握该工具,用于查询和计算某些特定的数据,并且PromQL是后续章节用来构造告警规则的基础语句
基本组成部分
1、指标名 (Metric Name):表示某一特定的时间序列数据
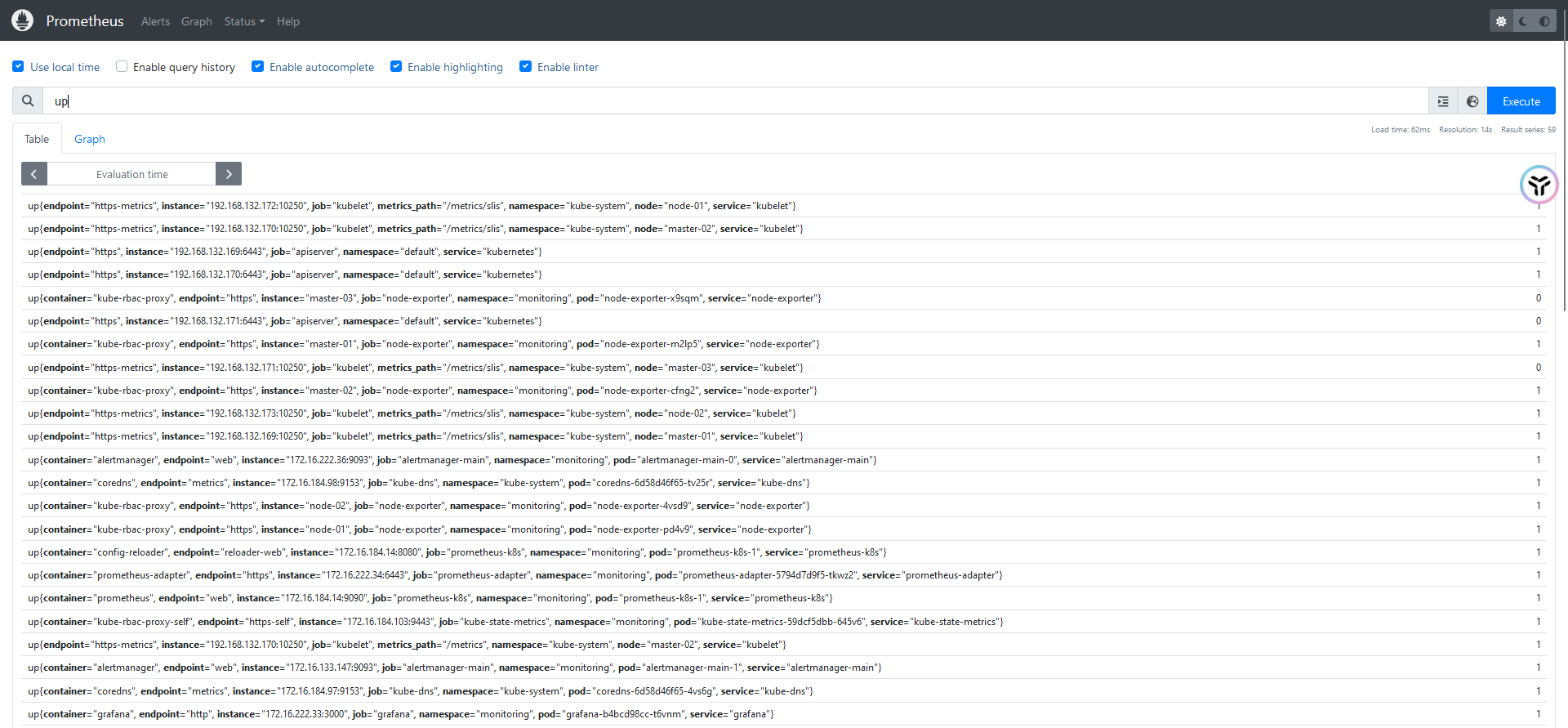
up #查询 up 指标,通常用于检查目标是否存活2、标签(Labels):使用 {} 过滤指标,基于键值对
http_requests_total{job="api-server", method="GET"} #查询 http_requests_total 指标中 job="api-server" 且 method="GET" 的数据3、时间范围 (Range Vector):使用 [时间范围] 表示一段时间的数据
rate(http_requests_total[5m]) #计算过去 5 分钟的每秒请求速率PromQL也支持如下表达式
!= #不等于;
=~ #表示等于符合正则表达式的指标;
!~ #和=~类似,=~表示正则匹配,!~表示正则不匹配。
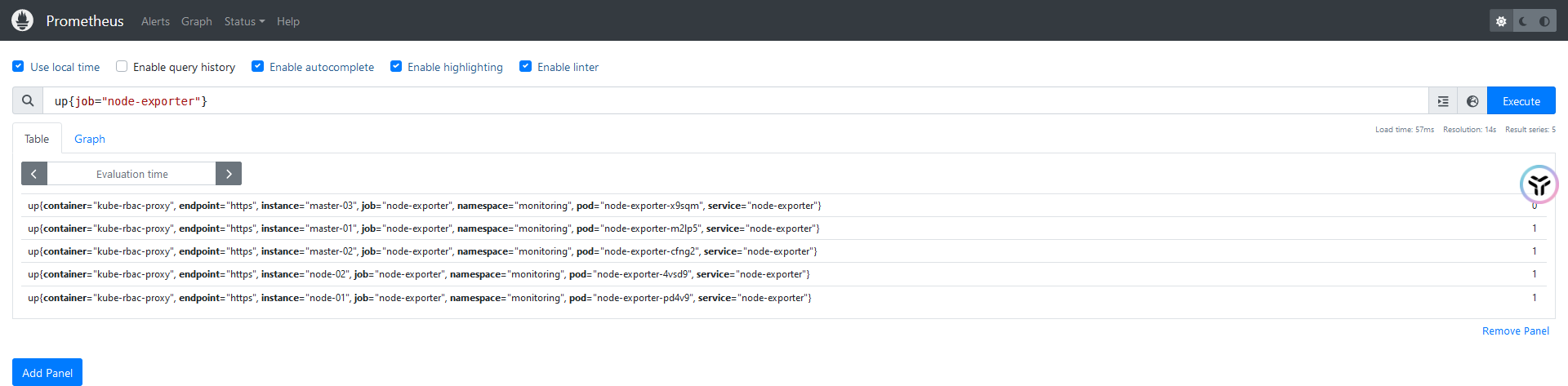
up{node!=master-01}查看Kubernetes集群中每个宿主机的磁盘总量

node_filesystem_size_bytes查询自定分区大小
node_filesystem_size_bytes{mountpoint="/"}查询分区不是/boot,且磁盘是/dev/开头的分区大小
node_filesystem_size_bytes{device=~"/dev/.*", mountpoint!="/boot"}查询主机 master-01 在最近 5 分钟可用的磁盘空间变化
node_filesystem_avail_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"}[5m]查询10分钟之前磁盘可用空间,指定offset参数
node_filesystem_avail_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"} offset 10m查询 10 分钟之前,5 分钟区间的磁盘可用空间的变化
node_filesystem_avail_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"}[5m] offset 10mPromQL 操作符
将查询到的主机磁盘的空间数据,转换为GB
node_filesystem_avail_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"} / 1024 / 1024 / 1024node_filesystem_avail_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"} / (1024 ^ 3)在master-01执行df -Th命令,与上图(主机磁盘空间)和下图(磁盘可用率)结果进行对比
[root@master-01 ~]# df -Th
Filesystem Type Size Used Avail Use% Mounted on
devtmpfs devtmpfs 2.4G 0 2.4G 0% /dev
tmpfs tmpfs 2.5G 0 2.5G 0% /dev/shm
tmpfs tmpfs 2.5G 30M 2.4G 2% /run
tmpfs tmpfs 2.5G 0 2.5G 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 39G 12G 27G 30% /查询master-01根分区磁盘可用率
node_filesystem_avail_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"} / node_filesystem_size_bytes{instance="master-01", mountpoint="/",device="/dev/mapper/centos-root"}查询所有主机根分区可用率
node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"}转化为百分百的形式
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100找到集群中根分区空间可用率大于 60%的主机
(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 > 60PromQL支持语法
| 参数 | 含义 |
|---|---|
| == | 相等 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| and | 并且 |
| or | 或 |
| unless | 排除 |
磁盘可用率大于 30%小于等于 60%的主机
30 < (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 <= 60(node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 > 30 and (node_filesystem_avail_bytes{mountpoint="/"} / node_filesystem_size_bytes{mountpoint="/"} ) * 100 <=60PromQL 常用函数
使用 sum 函数统计当前监控目标所有主机根分区剩余的空间
sum(node_filesystem_free_bytes{mountpoint="/"}) / 1024^3根据 statuscode 字段对http_request_total进行统计请求数据
sum(http_request_total) by (statuscode)根据 statuscode 和 handler 两个指标进一步统计
sum(http_request_total) by (statuscode, handler)PromQL还支持topk()、bottomk()、min()、max()、avg()、ceil()、floor()、sort()、sort_desc()等其他函数,在此处附带一篇文档,里面有关于PromQL函数的详细解析,有需要的读者可以认真阅读,会受益匪浅。
https://blog.caijxlinux.work/promql-learning.pdfAlertmanager 告警
Alertmanager 是 Prometheus 的一个组件,用于管理和处理警报。它可以接收来自 Prometheus 的警报并进行聚合、抑制、路由、通知等操作。使用 Alertmanager 可以确保警报被适当地管理,并且通知相关人员或者系统。
1、警报路由:根据警报的标签、级别或其他条件将警报路由到不同的接收器(如 Slack、邮件、Webhooks、OpsGenie、PagerDuty 等)。
2、警报抑制:在一定条件下,Alertmanager 可以抑制重复的警报,避免对同一问题发出多次告警。例如,当已经有一个警报正在处理时,可以抑制相同条件的其他警报。
3、警报聚合:将多个警报聚合成一个警报。例如,多个服务出现类似问题时,可以合并成一个警报,避免产生过多的噪音。
4、通知模板:支持自定义通知内容,通过 Go 模板对告警信息进行格式化。可以将告警内容定制为有用的、易读的格式。
5、持久化和分组:支持按标签对警报进行分组,避免同一个问题触发多个通知,减少通知的数量。
[root@master-01 ~]# vim alertmanager.yaml
# global块配置下的配置选项在本配置文件内的所有配置项下可见
global:
# 在Alertmanager内管理的每一条告警均有两种状态: "resolved"或者"firing". 在altermanager首次发送告警通知后, 该告警会一直处于firing状态,设置resolve_timeout可以指定处于firing状态的告警间隔多长时间会被设置为resolved状态, 在设置为resolved状态的告警后,altermanager不会再发送firing的告警通知.
resolve_timeout: 1h
# 邮件告警配置
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'jxcai@xxx.com'
smtp_auth_username: 'jxcai@xxx.com'
smtp_auth_password: 'DKxxx'
# HipChat告警配置
# hipchat_auth_token: '123456789'
# hipchat_auth_url: 'https://hipchat.foobar.org/'
# wechat
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'JJ'
wechat_api_corp_id: 'ww'
# 告警通知模板
templates:
- '/etc/alertmanager/config/*.tmpl'
# route: 根路由,该模块用于该根路由下的节点及子路由routes的定义. 子树节点如果不对相关配置进行配置,则默认会从父路由树继承该配置选项。每一条告警都要进入route,即要求配置选项group_by的值能够匹配到每一条告警的至少一个la belkey(即通过POST请求向altermanager服务接口所发送告警的labels项所携带的<labelname>),告警进入到route后,将会根据子路由routes节点中的配置项match_re或者match来确定能进入该子路由节点的告警(由在match_re或者match下配置的labelkey: labelvalue是否为告警labels的子集决定,是的话则会进入该子路由节点,否则不能接收进入该子路由节点).
route:
# 例如所有labelkey:labelvalue含cluster=A及altertname=LatencyHigh labelkey的告警都会被归入单一组中
group_by: ['job', 'altername', 'cluster', 'service','severity']
# 若一组新的告警产生,则会等group_wait后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在group_wait内合并为单一的告警后再发送
group_wait: 30s
# 再次告警时间间隔
group_interval: 5m
# 如果一条告警通知已成功发送,且在间隔repeat_interval后,该告警仍然未被设置为resolved,则会再次发送该告警通知
repeat_interval: 12h
# 默认告警通知接收者,凡未被匹配进入各子路由节点的告警均被发送到此接收者
receiver: 'wechat'
# 上述route的配置会被传递给子路由节点,子路由节点进行重新配置才会被覆盖
# 子路由树
routes:
# 该配置选项使用正则表达式来匹配告警的labels,以确定能否进入该子路由树
# match_re和match均用于匹配labelkey为service,labelvalue分别为指定值的告警,被匹配到的告警会将通知发送到对应的receiver
- match_re:
service: ^(foo1|foo2|baz)$
receiver: 'wechat'
# 在带有service标签的告警同时有severity标签时,他可以有自己的子路由,同时具有severity != critical的告警则被发送给接收者team-ops-mails,对severity == critical的告警则被发送到对应的接收者即team-ops-pager
routes:
- match:
severity: critical
receiver: 'wechat'
# 比如关于数据库服务的告警,如果子路由没有匹配到相应的owner标签,则都默认由team-DB-pager接收
- match:
service: database
receiver: 'team-ops-mails'
# 我们也可以先根据标签service:database将数据库服务告警过滤出来,然后进一步将所有同时带labelkey为database
- match:
severity: critical
receiver: 'wechat'
# 抑制规则,当出现critical告警时 忽略warning
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
# Apply inhibition if the alertname is the same.
# equal: ['alertname', 'cluster', 'service']
#
# 收件人配置
receivers:
- name: 'team-ops-mails'
email_configs:
- to: 'jxcai@xxx.com'
- name: 'wechat'
wechat_configs:
- send_resolved: true
corp_id: 'ww'
api_secret: 'JJ'
to_tag: '1'
agent_id: '1000002'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
message: '{{ template "wechat.default.message" . }}'
#- name: 'team-X-pager'
# email_configs:
# - to: 'team-X+alerts-critical@example.org'
# pagerduty_configs:
# - service_key: <team-X-key>
#
#- name: 'team-Y-mails'
# email_configs:
# - to: 'team-Y+alerts@example.org'
#
#- name: 'team-Y-pager'
# pagerduty_configs:
# - service_key: <team-Y-key>
#
#- name: 'team-DB-pager'
# pagerduty_configs:
# - service_key: <team-DB-key>
#
#- name: 'team-X-hipchat'
# hipchat_configs:
# - auth_token: <auth_token>
# room_id: 85
# message_format: html
# notify: true Alertmanager 的配置主要分为五大块:
| 参数 | 解析 |
|---|---|
| Global | 全局配置,主要用来配置一些通用的配置,比如邮件通知的账号、密码、SMTP服务器、微信告警等。Global 块配置下的配置选项在本配置文件内的所有配置项下可见,但是文件内其它位置的子配置可以覆盖 Global 配置 |
| Templates | 用于放置自定义模板的位置 |
| Route | 告警路由配置,用于告警信息的分组路由,可以将不同分组的告警发送给不同的收件人。比如将数据库告警发送给 DBA,服务器告警发送给 OPS |
| Inhibit_rules | 告警抑制,主要用于减少告警的次数,防止“告警轰炸”。比如某个宿主机宕机,可能会引起容器重建、漂移、服务不可用等一系列问题,如果每个异常均有告警,会一次性发送很多告警,造成告警轰炸,并且也会干扰定位问题的思路,所以可以使用告警抑制,屏蔽由宿主机宕机引来的其他问题,只发送宿主机宕机的消息即可 |
| Receivers | 告警收件人配置,每个 receiver 都有一个名字,经过 route 分组并且路由后需要指定一个 receiver,就是在此位置配置的 |
Alertmanager 路由规则
route:
receiver: Default
group_by:
- namespace
- job
- alertname
routes:
- receiver: Watchdog
match:
alertname: Watchdog
- receiver: Critical
match:
severity: critical
group_wait: 30s
group_interval: 5m
repeat_interval: 10m| 参数 | 解析 |
|---|---|
| receiver | 告警的通知目标,需要和 receivers 配置中 name 进行匹配。需要注意的route.routes 下也可以有 receiver 配置,优先级高于 route.receiver 配置的默认接收人,当告警没有匹配到子路由时,会使用 route.receiver 进行通知,比如上述配置中的Default |
| group_by | 分组配置,值类型为列表。比如配置成['job', 'severity'],代表告警信息包含job 和 severity 标签的会进行分组,且标签的 key 和 value 都相同才会被分到一组 |
| continue | 决定匹配到第一个路由后,是否继续后续匹配。默认为 false,即匹配到第一个子节点后停止继续匹配 |
| match | 一对一匹配规则,比如 match 配置的为 job: mysql,那么具有 job=mysql 的告警会进入该路由 |
| match_re | 和 match 类似,只不过是 match_re 是正则匹配 |
| group_wait | 告警通知等待,值类型为字符串。若一组新的告警产生,则会等 group_wait后再发送通知,该功能主要用于当告警在很短时间内接连产生时,在 group_wait 内合并为单一的告警后再发送,防止告警过多,默认值 30s |
| group_interval | 同一组告警通知后,如果有新的告警添加到该组中,再次发送告警通知的时间,默认值为 5m |
| repeat_interval | 如果一条告警通知已成功发送,且在间隔 repeat_interval 后,该告警仍然未被设置为 resolved,则会再次发送该告警通知,默认值 4h |
Alertmanager配置邮件告警
由于本次实验全部组件都使用容器搭建,所有Alertmanager的配置文件是通过secret定义的,修改对应的配置文件,添加的内容进行分段解释
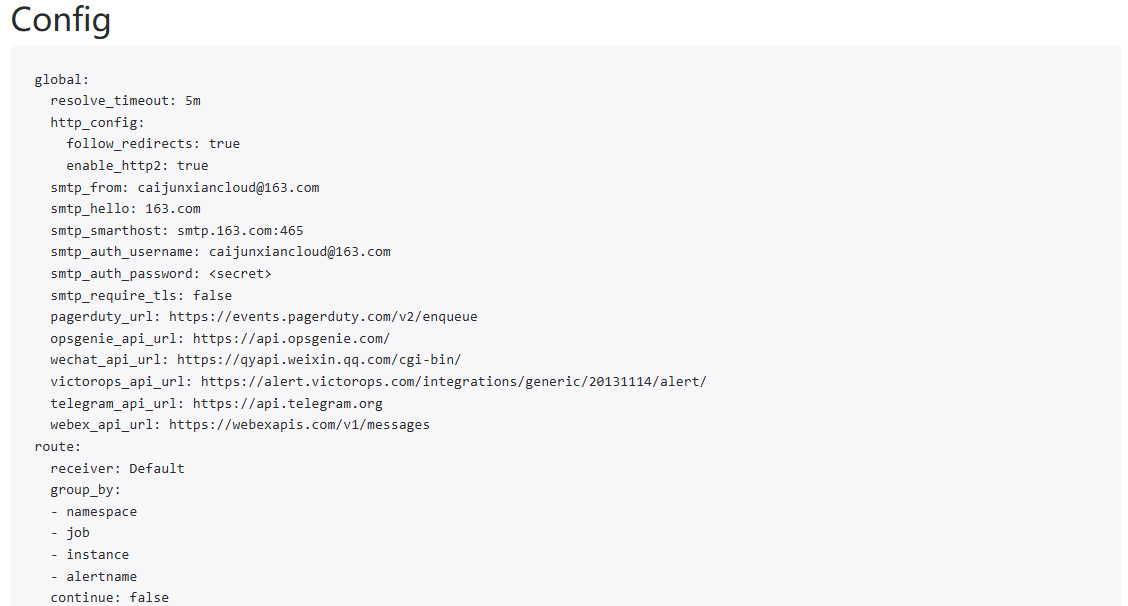
[root@master-01 ~]# vim kube-prometheus/manifests/alertmanager-secret.yaml在global下方添加smtp(发信)配置,本次实验使用163邮箱,填写对应的账号名称、SMTP服务器地址和调用SMTP服务器的密码
...省略部分输出...
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
smtp_from: "caijunxiancloud@163.com"
smtp_smarthost: "smtp.163.com:465"
smtp_hello: "163.com"
smtp_auth_username: "caijunxiancloud@163.com"
smtp_auth_password: "AS56...dsM"
smtp_require_tls: false
...省略部分输出...在receivers下配置接收告警的账号
...省略部分输出...
"receivers":
- "name": "Default"
"email_configs":
- to: "caijunxiancloud@163.com"
send_resolved: true
...省略部分输出...在route下添加分组方式,添加job、alertname和instance
...省略部分输出...
"route":
"group_by":
- "namespace"
- "job"
- "alertname"
- "instance"
...省略部分输出...配置完成后,重新加载Secret配置文件
[root@master-01 ~]# kubectl replace -f kube-prometheus/manifests/alertmanager-secret.yaml
secret/alertmanager-main replaced修改alertmanager的Service端口类型为NodePort,已经重复介绍过多次,此处不再赘述(9093端口为Web UI端口,8080端口为alertmanager和Prometheus通信的端口,读者不要混淆)
[root@master-01 ~]# kubectl get svc -n monitoring | grep alertmanager-main
alertmanager-main NodePort 10.96.85.152 <none> 9093:31016/TCP,8080:31810/TCP 7d21h通过Service暴露的31016端口访问alertmanager的UI界面,可以观察到首页的Alerts界面已经增加了分组方式

单击上方导航栏的Status按钮,下拉至出现Config字段,可以观察到配置已经发生变化
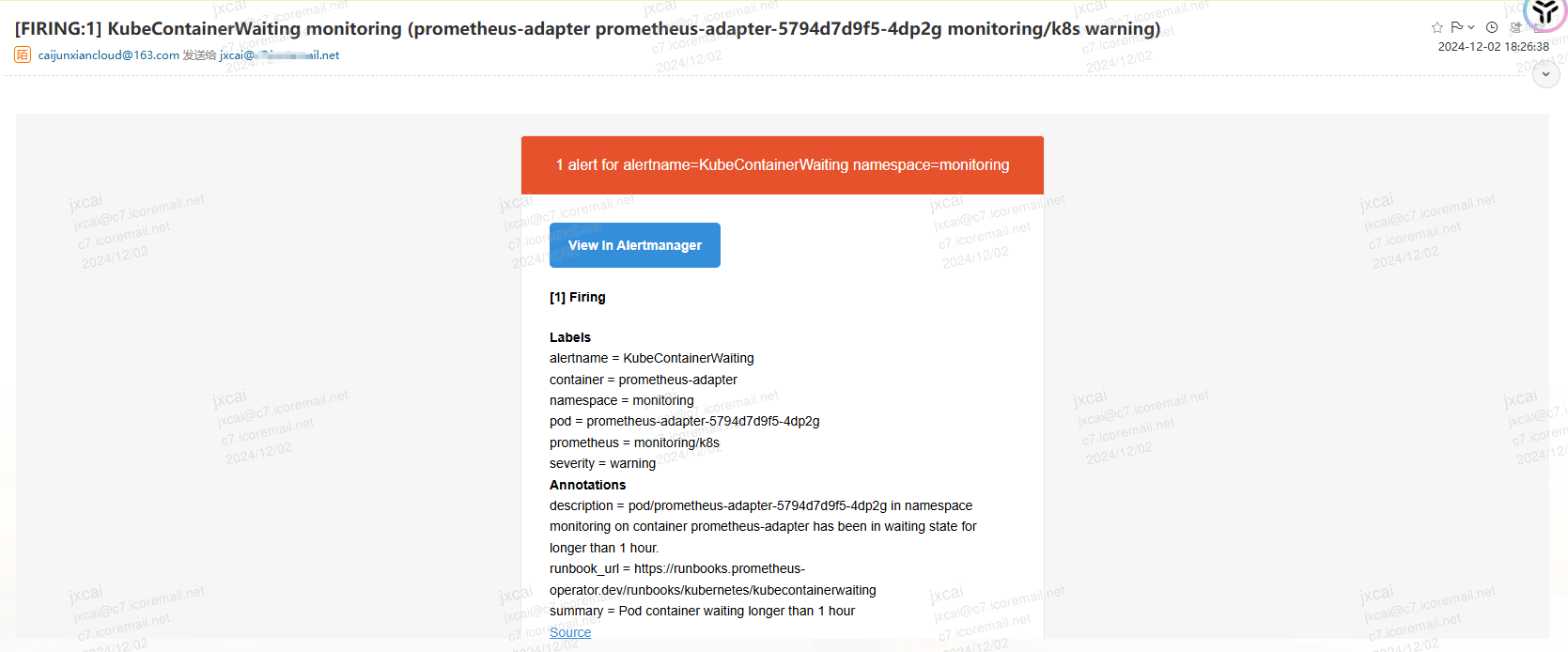
登录对应接收告警信息的邮箱账号,已经可以观察到对应的告警信息了(读者在使用时,只要等找到可以用于发信的SMTP服务器即可,本质上就是邮件发送)。此处的截图可以观察到是发送到其他的邮箱账户
Alertmanager 企业微信通知
读者需要先注册企业,如果已经有企微并且有对应的后台权限,可以忽略该步骤。注册链接如下
https://work.weixin.qq.com/注册完成后,进入登录界面,单击上方导航栏中,我的企业按钮。在页面的最下面找到企业 ID(corp_id)并记录

单击上方导航通讯录按钮,创建对应接收告警信息的部门。对应部门的ID需要进行记录
单击上方导航栏应用管理按钮,在页面最下方找到自建,单击创建应用

选择对应的部门或成员
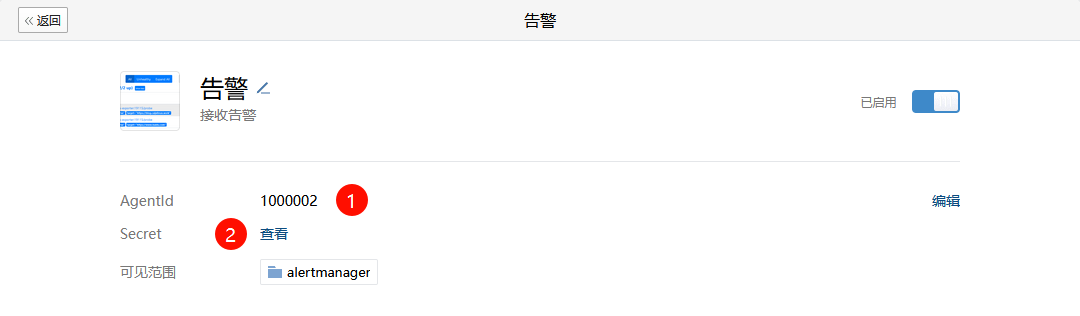
创建完成后,记录该应用对应的Agentld和Secret(注意:Secret单击查看后,需要前往企业微信内部查看)
注意:添加完成后,旧版本的企微直接修改alertmanager配置文件即可,但是新版的企业如果需要使用对应的接口,需要添加可信域名和可信IP,步骤如下
单击企微上方导航栏,在页面最后找到网页授权及JS-SDK。(配置该步骤需要完成前置条件:首先必须有一个公网可以访问的域名,并且该域名需要备案。其次需要将授权文件放在域名的根目录下,即通过https://域名/授权文件 可以直接访问该文件)。授权文件在网页会提供下载链接。配置完成后结果如下
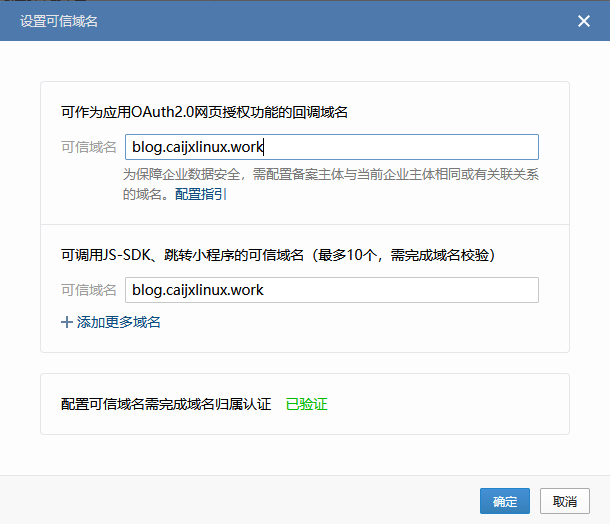
注意,配置完成后,依旧是无法实现企微告警,但是此处先不进行其他操作,按照大部分网上的教程继续。
修改alertmanager-secret配置文件,添加全局配置,增加企微对应的API接口和企业码
[root@master-01 ~]# vim kube-prometheus/manifests/alertmanager-secret.yaml
"global":
"resolve_timeout": "5m"
wechat_api_url: "https://qyapi.weixin.qq.com/cgi-bin/"
wechat_api_corp_id: "ww8...c7c"
...省略部分输出...receivers字段下,增加企微对应的配置
- name: wechat
wechat_configs:
- send_resolved: true
to_party: 2 #部门ID
to_user: '@all' #部门的所有人接收告警信息,也可以指定对应用户
agent_id: 1000002 #应用的Agentld
api_secret: "58zQz...vHM1is" #应用的Secret
...省略部分输出...修改子路由配置,将Watchdog的告警发送给wechat接收者
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "wechat"
...省略部分输出...如果读者想快速看到效果,可以修改route字段下的 repeat_interval参数
"repeat_interval": "1m"修改完成后,重载Alertmanager Secret配置文件,等待一段时间在Web UI看到配置文件发生变化
[root@master-01 ~]# kubectl replace -f kube-prometheus/manifests/alertmanager-secret.yaml
secret/alertmanager-main replaced此时,读者会发现,企微仍然无法接收告警,通过查看alertmanager容器的日志文件,可以发现如下提示
ts=2024-12-02T16:40:03.083Z caller=dispatch.go:353 level=error component=dispatcher msg="Notify for alerts failed" num_alerts=1 err="wechat/wechat[0]: notify retry canceled due to unrecoverable error after 1 attempts: not allow to access from your ip, hint: [1733157603031422631558704], from ip: 120.230.86.159, more info at https://open.work.weixin.qq.com/devtool/query?e=60020"通过查找对应的错误码,可以发现是出口IP被拒绝了,所以需要将出口IP添加到企业可信IP内。该选项在应用管理下。添加后结果如下
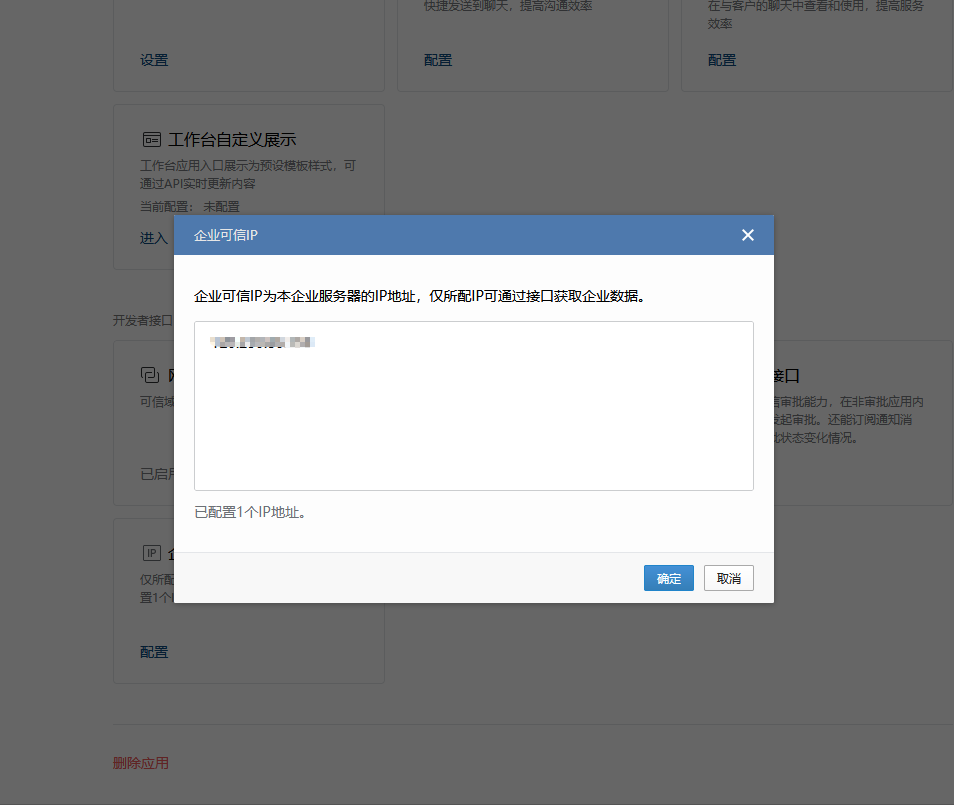
企微发送告警结果如下
自定义告警模板
使用alertmanager自带的告警模板,在告警繁多的情况下,不易于定位告警内容,针对此问题,使用自定义的告警模板进行告警通知
此处将整个配置文件贴出,供读者参考(严格遵守缩进)
[root@master-01 ~]# cat kube-prometheus/manifests/alertmanager-secret.yaml
apiVersion: v1
kind: Secret
metadata:
labels:
app.kubernetes.io/component: alert-router
app.kubernetes.io/instance: main
app.kubernetes.io/name: alertmanager
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 0.27.0
name: alertmanager-main
namespace: monitoring
stringData:
wechat.tmpl: |-
{{ define "wechat.default.messages" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
==========异常告警==========
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情:
{{ $alert.Annotations.message }}{{ $alert.Annotations.description }}; {{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
===========END============
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
==========异常恢复==========
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情:
{{ $alert.Annotations.message }}{{ $alert.Annotations.description }}; {{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
===========END============
{{- end }}
{{- end }}
{{- end }}
{{- end }}
alertmanager.yaml: |-
"global":
"resolve_timeout": "5m"
smtp_from: "caijunxiancloud@163.com"
smtp_smarthost: "smtp.163.com:465"
smtp_hello: "163.com"
smtp_auth_username: "caijunxiancloud@163.com"
smtp_auth_password: "S...56fM"
smtp_require_tls: false
wechat_api_url: "https://qyapi.weixin.qq.com/cgi-bin/"
wechat_api_corp_id: "ww8...c7c"
templates:
- '/etc/alertmanager/config/*.tmpl'
"inhibit_rules":
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = critical"
"target_matchers":
- "severity =~ warning|info"
- "equal":
- "namespace"
- "alertname"
"source_matchers":
- "severity = warning"
"target_matchers":
- "severity = info"
- "equal":
- "namespace"
"source_matchers":
- "alertname = InfoInhibitor"
"target_matchers":
- "severity = info"
"receivers":
- "name": "Default"
"email_configs":
- to: "jxcai@c7.icoremail.net"
send_resolved: true
- name: wechat
wechat_configs:
- send_resolved: true
to_party: 1
to_user: '@all'
agent_id: 1000002
api_secret: "58z...vHM1is"
message: '{{ template "wechat.default.messages" . }}'
- "name": "Watchdog"
- "name": "Critical"
- "name": "null"
"route":
"group_by":
- "namespace"
- "job"
- "instance"
- "alertname"
"group_interval": "5m"
"group_wait": "30s"
"receiver": "Default"
"repeat_interval": "12h"
"routes":
- "matchers":
- "alertname = Watchdog"
"receiver": "wechat"
- "matchers":
- "alertname = InfoInhibitor"
"receiver": "null"
- "matchers":
- "severity = critical"
"receiver": "Critical"
type: Opaque上面的配置文件,修改了三处,添加了对应的模板文件
wechat.tmpl: |-
{{ define "wechat.default.messages" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
...省略部分输出...指定了模板的位置
templates:
- '/etc/alertmanager/config/*.tmpl'wechat应用该模板(注意:{{ template "wechat.default.message" . }}配置的 wechat.default.message,是模板文件define 定义的名称:{{ define "wechat.default.message" }},并非文件名称)
api_secret: "58z...vHM1is"
message: '{{ template "wechat.default.messages" . }}'
...省略部分输出... 配置完成后,重启Alertmanager Secret文件,等待Web UI界面重新生成配置(大约需要5分钟,才能重新读取配置)
[root@master-01 ~]# kubectl replace -f kube-prometheus/manifests/alertmanager-secret.yaml secret/alertmanager-main replaced企微此时告警模板
计划内维护暂停告警Silence
对于已经知晓的告警或者需要延后处理的告警,可以使用Silence功能,类似于icinga的dowmtime功能

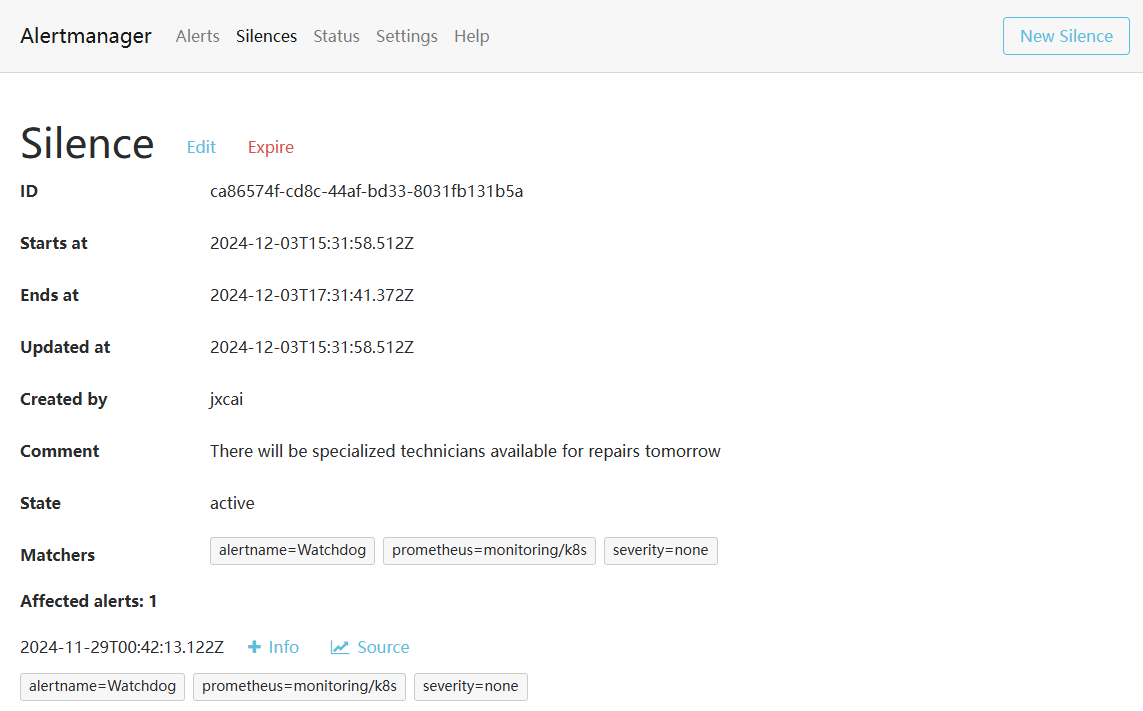
PrometheusRule
Prometheus 的告警机制主要依赖 规则评估 和 告警管理 两个部分:
-
规则评估
Prometheus 使用 告警规则(Alerting Rules) 来定义告警条件,这些规则通常配置在 Prometheus 的 rules.yml 文件中,或者通过 PrometheusRule 自定义资源定义(CRD)在 Kubernetes 环境中应用 -
告警管理
当 Prometheus 发现一个告警条件满足时:生成告警状态(Pending → Firing)。将告警信息发送到 Alertmanager。
PrometheusRule 是 Kubernetes 环境中的 自定义资源定义(CRD),用于在集群中定义 Prometheus 的告警规则。其作用:提供了一种将告警规则以 Kubernetes 资源形式管理的方式。集中化管理:与 Kubernetes 的声明式配置集成,方便版本控制和动态更新。在 Kubernetes 中,Prometheus 会自动发现集群中定义的 PrometheusRule 资源,并加载其中的告警规则。
查看默认配置的告警策略
[root@master-01 ~]# kubectl get prometheusrules -n monitoring
NAME AGE
alertmanager-main-rules 9d
grafana-rules 9d
kube-prometheus-rules 9d
kube-state-metrics-rules 9d
kubernetes-monitoring-rules 9d
node-exporter-rules 9d
prometheus-k8s-prometheus-rules 9d
prometheus-operator-rules 9d通过-oyaml 查看某个 rules 的详细配置
[root@master-01 ~]# kubectl get prometheusrules -n monitoring node-exporter-rules -oyaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
...省略部分输出...
spec:
groups:
- name: node-exporter
rules:
- alert: NodeFilesystemSpaceFillingUp
annotations:
description: Filesystem on {{ $labels.device }}, mounted on {{ $labels.mountpoint
}}, at {{ $labels.instance }} has only {{ printf "%.2f" $value }}% available
space left and is filling up.
runbook_url: https://runbooks.prometheus-operator.dev/runbooks/node/nodefilesystemspacefillingup
summary: Filesystem is predicted to run out of space within the next 24 hours.
expr: |
(
node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!="",mountpoint!=""} * 100 < 15
and
predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!="",mountpoint!=""}[6h], 24*60*60) < 0
and
node_filesystem_readonly{job="node-exporter",fstype!="",mountpoint!=""} == 0
)
for: 1h
labels:
severity: warning
...省略部分输出...| 参数 | 解析 |
|---|---|
| alert | 告警策略的名称 |
| annotations | 告警注释信息 |
| expr | 告警表达式 |
| for | 评估等待时间,告警持续多久才会发送告警数据 |
| labels | 告警的标签,用于告警的路由 |
域名访问延迟告警
假设需要对域名访问延迟进行监控,访问延迟大于 0.1 秒进行告警,此时可以创建一个PrometheusRule 如下(注意:真实情况下,不需要将阈值设置如此敏感,此处只是为了实验展示效果)
[root@master-01 ~]# cat blackbox.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: blackbox
namespace: monitoring
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: blackbox-exporter
prometheus: k8s
role: alert-rules
spec:
groups:
- name: blackbox-exporter
rules:
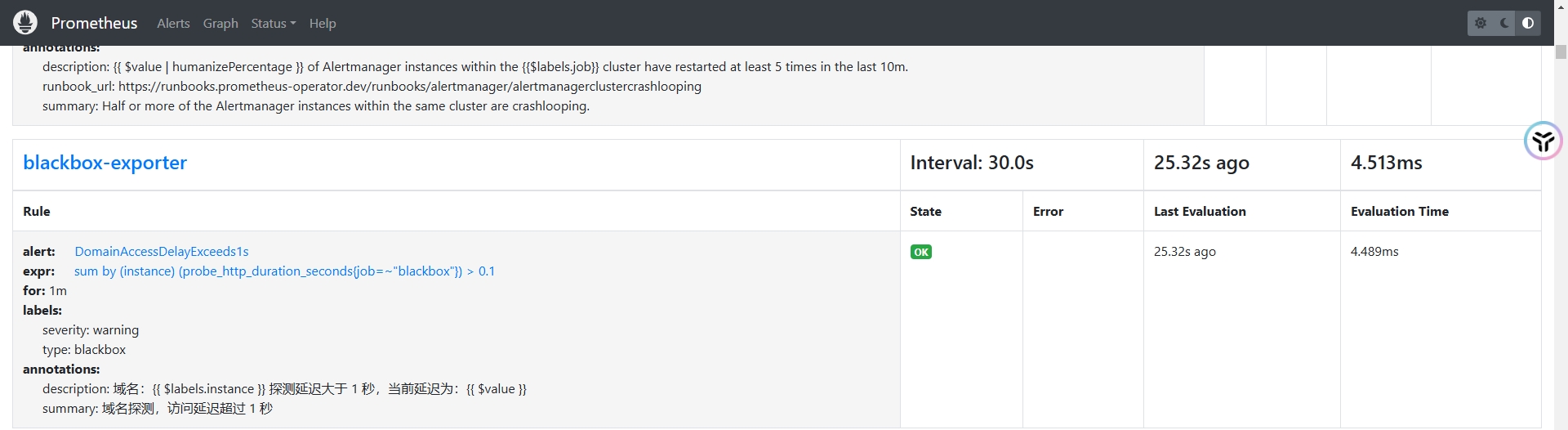
- alert: DomainAccessDelayExceeds1s
annotations:
description: 域名:{{ $labels.instance }} 探测延迟大于 1 秒,当前延迟为:{{ $value }}
summary: 域名探测,访问延迟超过 1 秒
expr: sum(probe_http_duration_seconds{job=~"blackbox"}) by (instance) > 0.1
for: 1m
labels:
severity: warning
type: blackbox创建资源
[root@master-01 ~]# kubectl create -f blackbox.yaml
prometheusrule.monitoring.coreos.com/blackbox created
[root@master-01 ~]# kubectl get -f blackbox.yaml
NAME AGE
blackbox 39s依次单击Prometheus UI界面上方导航栏→Status→Rules,找到配置的规则
此时由于阈值设置为0.1秒,所以Prometheus的Alerts界面也会出现告警,Alertmanager的路由规则并没有针对黑盒监控的接受者,所以会匹配到Default的Receive,推送邮件通知

在本文内,只列举了一种告警的配置方法,但是在实例的应用场景当中,可能需要配置多种监控和告警指标,读者可以使用grafana的案例进行参考。
选择某个模板,单击Explore按钮
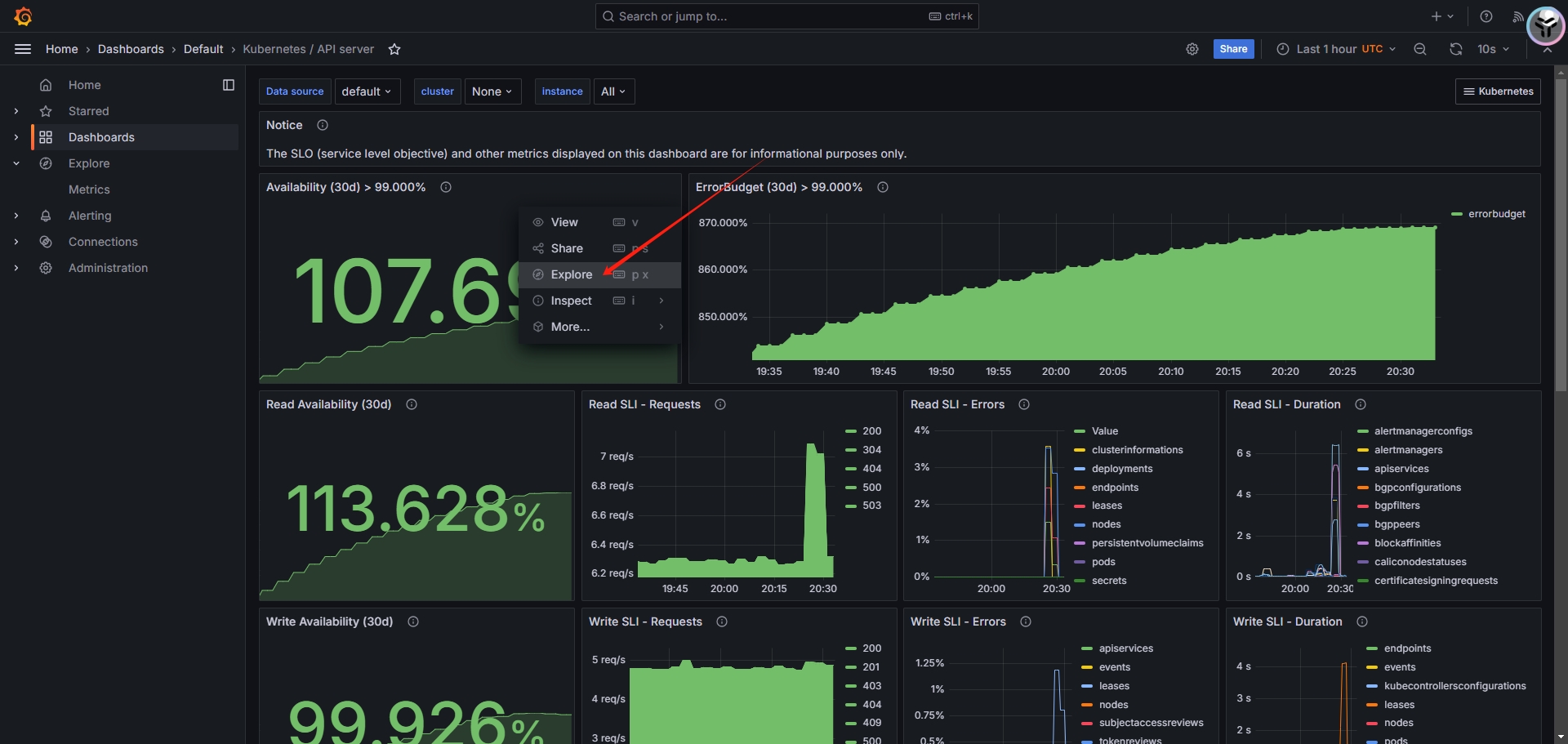
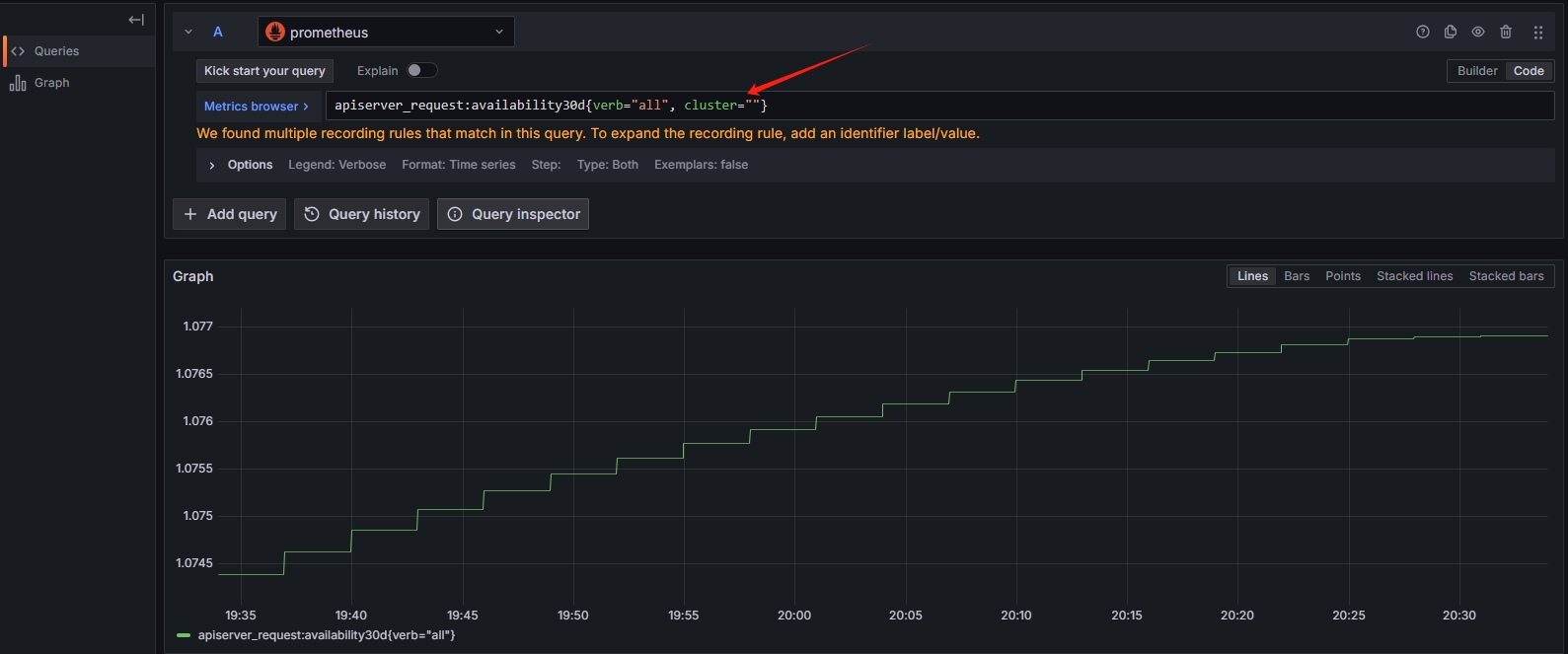
出现的界面即为采集数据的监控语句,通过对应的判断条件,比如大于等于某个阈值,即可修改为对应的监控条件
书山有路勤为径,学海无涯苦作舟
书山有路勤为径